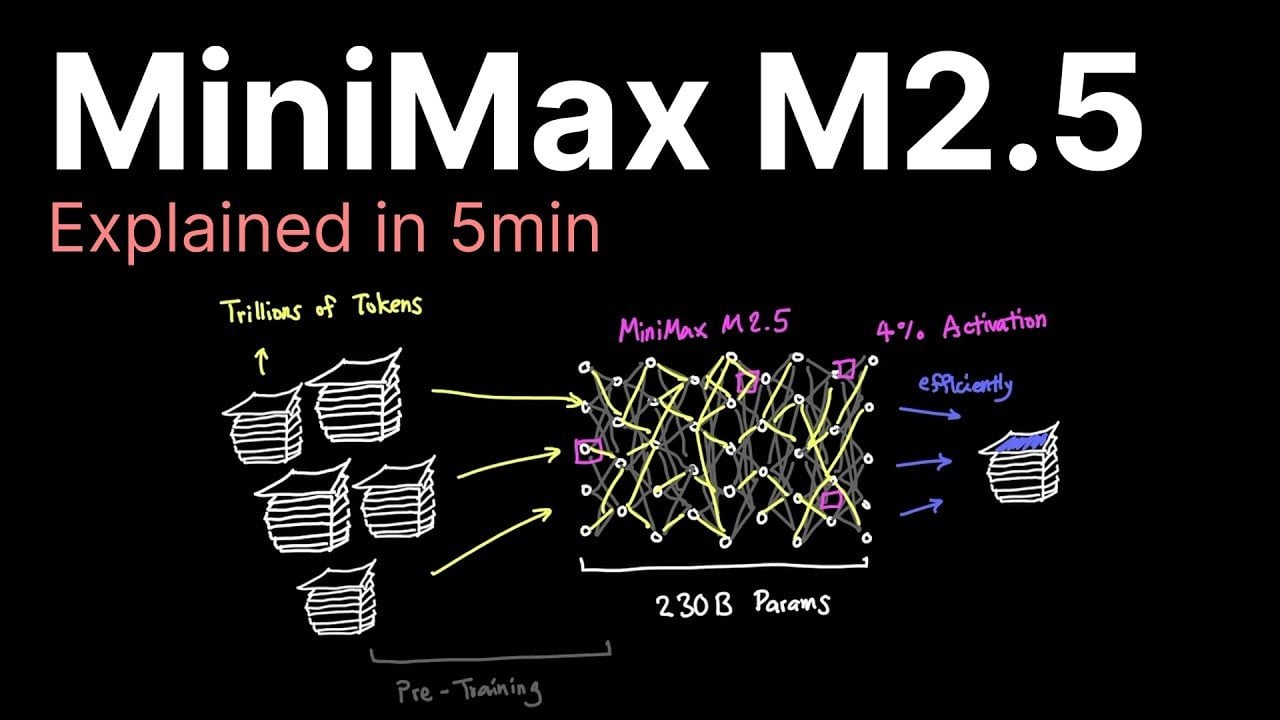
The MiniMax M2.5 is an advanced AI model designed to balance high performance with cost efficiency, as explained by Caleb Writes Code. Building on its predecessor, the M2.1, this model incorporates a sparse activation mechanism that activates only 10 billion parameters per token, or 4% of its total 230 billion parameters. This approach enables the […]
The post MiniMax M2.5 Uses 10B Active Parameters per Token, Aiming for Cheaper Always-On Agents appeared first on Geeky Gadgets.


