Kansas City has bought more than 4,500 MacBook Neos for its students Posted on 20/05/2026 by Anna Washenko The newly "all-Apple district" will replace 30,000 Windows and Chromebook devices across its public schools.
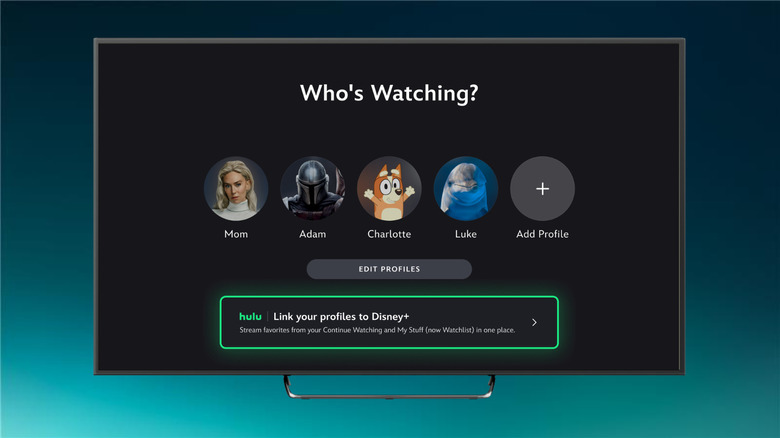
Hulu bundle subscribers can now access their watch history and recs in the Disney+ app Posted on 20/05/2026 by Anna Washenko Even though Disney really wants you in its own app, it isn't killing off Hulu.
Discord now has end-to-end encryption on all calls Posted on 19/05/2026 by Anna Washenko It's a win for privacy on the social app.
Firefox AI guardrails arrive for mobile Posted on 19/05/2026 by Anna Washenko The feature lets you turn all AI enhancements off with one tap.
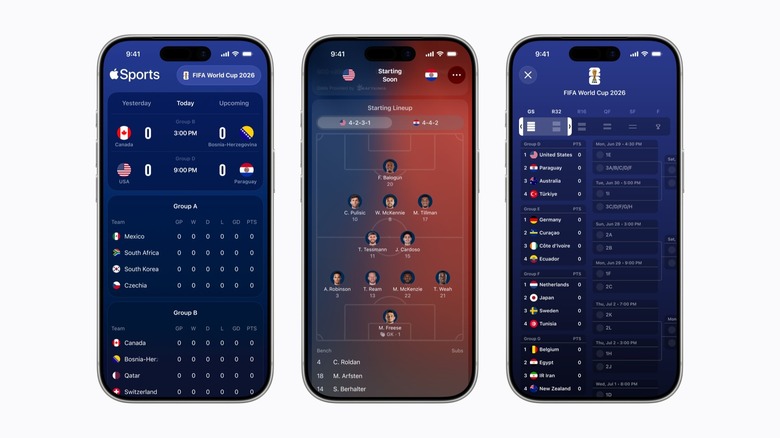
The Apple Sports app expands to 90 new markets ahead of the World Cup Posted on 19/05/2026 by Anna Washenko Apple is targeting World Cup fans ahead of this summer's tournament.
Minnesota passes prediction markets ban Posted on 19/05/2026 by Anna Washenko The CFTC has already sued to prevent the Minnesota's prediction markets ban.
The Google AI Ultra plan now starts at $100 a month Posted on 19/05/2026 by Anna Washenko Google's most expensive AI plan is now a little cheaper.
I/O 2026 is bringing more AI to Google Play Posted on 19/05/2026 by Anna Washenko Play Games Sidekick is also getting a wider rollout.
PSA: The first F1 race on Netflix is this weekend Posted on 18/05/2026 by Anna Washenko Catch the F1 Canadian Grand Prix live on a service that isn't Apple.
Disney faces a class action lawsuit over facial recognition tech Posted on 18/05/2026 by Anna Washenko The complaint says park visitors don't get sufficient notice they're being scanned.