The UK’s Competition and Markets Authority (CMA) is recommending measures to give publishers more control over how their content is used in Google’s AI overviews. The aim is to “provide a fairer deal for content publishers, particularly news organizations,” the CMA’s chief executive Sarah Cardell said in a press release.
With Google accounting for more than 90 percent of search inquiries in the UK, the CMA recently designated the company with “strategic market status” for search under the Digital Market Act. That allows the regulator to apply “conduct requirements” on Google to promote competition and avoid antitrust issues.
With those new powers, the CMA proposed a number of measures today. The first is a set of controls that would allow publishers to opt out of their content being used for features like AI Overviews or to train AI models. Google would also need to properly attribute publisher content.
Another measure would require Google to apply fair search result rankings for businesses, with an “effective process for raising and investigating issues.” Google would also need to provide a “choice screen” for alternative search options on Android mobile and Chrome browsers.
“These targeted and proportionate actions would give UK businesses and consumers more choice and control over how they interact with Google’s search services — as well as unlocking greater opportunities for innovation across the UK tech sector and broader economy,” Cardell said in a statement.
In response, Google wrote that it’s “exploring updates to let sites specifically opt out of Search generative AI features.” The aim, it said, is to keep search helpful for people who want information quickly while allowing publishers to better manage content. “Any new controls need to avoid breaking Search in a way that leads to a fragmented or confusing experience for people,” the company wrote, adding that it’s “optimistic” it can meet the CMA’s requirements.
When its new designation was announced in October 2025, Google complained that some of the proposed interventions would inhibit UK innovation and growth. Citing a study, the company said that similar measures imposed by the European Union produced “negative results” that “have cost businesses $114 billion.”
This article originally appeared on Engadget at https://www.engadget.com/ai/uk-wants-to-give-web-publishers-a-fairer-deal-with-googles-ai-overviews-132742850.html?src=rss
Windscribe is a virtual private network (VPN) with intense "How do you do, fellow kids?" energy. It has servers in 69 countries and an annual plan that costs $69, an obsession with the sex number that rivals Elon Musk's. I'm shocked that it doesn't have a subscription costing $4.20 per month.
But there's another side to Windscribe's cringe: an obsession with independence and a Bernie Sanders-like anger on behalf of an exploited public. In a market where the best VPNs aim for professionalism, Windscribe aspires to be punk. Its iconoclasm may have led it to develop an app that looks like ExpressVPN in a trash compactor, but it also spurred Windscribe to offer a strong free plan and forgo financial relationships with VPN reviewers. That attitude earned it a spot on my list of the best free VPNs.
Although Windscribe's heart is in the right place, my job is to figure out whether that translates into a good product. I used our rigorous VPN testing procedure to rate Windscribe in 11 categories. You can find my results in the table below and a final verdict at the end of the review.
Editor's note (1/27/26): We've overhauled our VPN coverage to provide more detailed, actionable buying advice. Going forward, we'll continue to update both our best VPN list and individual reviews (like this one) as circumstances change. Most recently, we added official scores to all of our VPN reviews.Check out how we test VPNs to learn more about the new standards we're using.
Findings at a glance
Category
Notes
Installation and UI
Installation and setup are always straightforward
Apps look very similar on Windows, macOS, iOS and Android
App design is overly compact and often impenetrable, but hides a solid program
Browser extensions allow one-click bypassing of security features on the current page, much like common ad blockers
Speed
Average latency below 300 worldwide
Some slowdown in download and upload speeds, but not severe
Speeds were highly consistent everywhere except some African servers
Security
Six solid protocols — WireGuard, IKEv2, and four based on OpenVPN
Most protocols available on all platforms, except IKEv2 on Android
No leaks detected, even while switching servers
Packets are encrypted as expected
Pricing
$9 per month, $69 for one year ($5.75 per month)
Custom plans cost $1 per country plus $1 for unlimited data; must spend at least $3
Static IPs available for $2 per month or $8 per month for a residential address
Free plan gives you 10 locations and 10GB per month with a confirmed email
Bundles
Shares coupon codes for various discounts on five "partners in privacy"
Privacy policy
Retains very little information, none of it personally identifiable
Can make an account without an email address
All apps have been audited by independent overseers
Fought Greek court case in 2025 because it had no logs to turn over
Virtual location change
15 different servers in five locations unblocked Netflix
Content changed each time, suggesting the destination site was completely fooled
Server network
193 server locations in 122 cities across 71 countries
Only two virtual server locations in the entire network
Real servers in Russia and India risk abrupt shutdowns
Features
Standout extras include the customizable R.O.B.E.R.T blocker and split tunneling on Windows, Mac and Android
Network Options offers lots of automation choices, but terminology makes it needlessly confusing
Includes obfuscation to get online in restrictive regions
Firewall is a stronger version of a kill switch, preventing any access unless the VPN is connected
Customer support
Knowledgebase search bar is good at finding articles, and articles themselves are useful
Garry AI chatbot is helpful, but pushed way too hard at the expense of access to human agents
Active Reddit and Discord communities for peer-to-peer help
Background check
Founded in Canada in 2016
No significant controversies in 10 years
Canada is a Five Eyes nation, but this shouldn't matter if Windscribe is keeping to its no logs policy
Installing, configuring and using Windscribe
The first step is always to figure out how easy or hard the VPN is to use. Windscribe and other VPNs are important tools, but you'll never use them if the UI gets in the way. I tested Windscribe's desktop apps on Windows and Mac, its mobile apps on iOS and Android and its Chrome and Firefox browser extensions.
To start with, let me say that installing Windscribe is a breeze no matter where you do it. The downloaders and installers handle their own business, only requiring you to grant a few permissions. The apps arrive on your system ready to use out of the box.
Windows
The first thing you'll notice about Windscribe is that it's not even slightly interested in looking like any other VPN. It crams everything into an extremely compact window, which has some advantages — mainly that it's easy to operate it while looking at another app. On the downside, well, it looks like this.
Windscribe's UI on a Windows laptop.
Sam Chapman for Engadget
The Windscribe team will probably just say that I'm brainwashed by the establishment, but there's a good reason that most VPNs choose designs with a little more space. This fiddly console, most of which is taken up by information you can't interact with, is likely to confirm all a newcomer's worst fears about using a VPN. Private Internet Access had a similar problem of tightening its app design to the point of being incomprehensible.
The problems persist when you get to the settings page. It's easy to make sense of a VPN without technical knowledge, but Windscribe's preferences menu does everything it can to obscure that truth. Highly technical features are mixed in with options for casual users, and the explanatory blurbs usually cloud the issue even further.
Even the "Look & Feel" settings somehow manage to be confusing. What is the difference between the Stretch, Fill and Tile modes for aspect ratio? What the heck is a Bundled background, and what does it matter whether it's Square, Palm, Ripple, Drip or Snow? The answers to all these can be found by playing around or looking in the knowledgebase, but a VPN really shouldn't require that for its most basic toggles.
Once you get used to Windscribe and learn where to find the features that actually matter, it runs quite smoothly. Connections are never delayed and there are none of the random error messages that have dogged me on other VPNs. In a world of VPNs that look great but run clunkily, Windscribe has built one that looks terrible but runs great. I can't complain about how well it works, but is it too much to ask for a provider that does both? (Oh, wait, that's Proton VPN.)
Mac
Windscribe's macOS app is almost identical to its Windows app. That deserves praise in itself — you'll get much the same experience no matter which type of computer you use. But it also means the Mac app shares the same problems.
Windscribe's app for Mac desktops and laptops.
Sam Chapman for Engadget
There's the same overly compact design cluttered with too much information. The same technobabble-filled options menu. And the same fundamental solidity underlying it all: a VPN that does the job beautifully but has no interest in being accessible. It would be a mistake to write Windscribe off because of its app design, but it's important to know what you'll have to work through.
Android
One thing I can't fault Windscribe for is a lack of consistency. The Android app looks a lot like the Windows and Mac apps, only lightly adapted for the mobile format. On these devices, the design decisions make more sense — the UI writing is still impenetrable for casual users, but the compact pages look a lot more normal on a phone screen.
A comparison of Windscribe's extremely similar apps on Android and Mac.
Sam Chapman for Engadget
iOS
There's not a lot to say about Windscribe on iOS that I haven't already said about the other three main platforms. Looking over all my screenshots, it seems fairly clear that Windscribe's problems — much like PIA's — come from starting on mobile and trying to make that same design work on desktop. It's still not great to look at, but I can at least see where they're coming from.
Windscribe's iOS app.
Sam Chapman for Engadget
Browser extensions
Windscribe's extensions for Chrome and Firefox look a little like its desktop and mobile VPN apps, but they act a little differently. They serve the same basic purpose as the standalone apps — changing your IP address and location — but they're also customizable ad blockers for the web page you're currently on.
Windscribe's Google Chrome extension.
Sam Chapman for Engadget
For example, in the image above, I can control what location Google perceives me to be in. But I can also control what gets blocked by choosing to let Google bypass certain features. Clicking the leftmost button makes the current website skip the VPN tunnel. The central button shuts off the ad blocker and the right-hand button shuts off the features on the Privacy section of the preferences menu. Like everything else about Windscribe, it's unintuitive but works great once you figure it out.
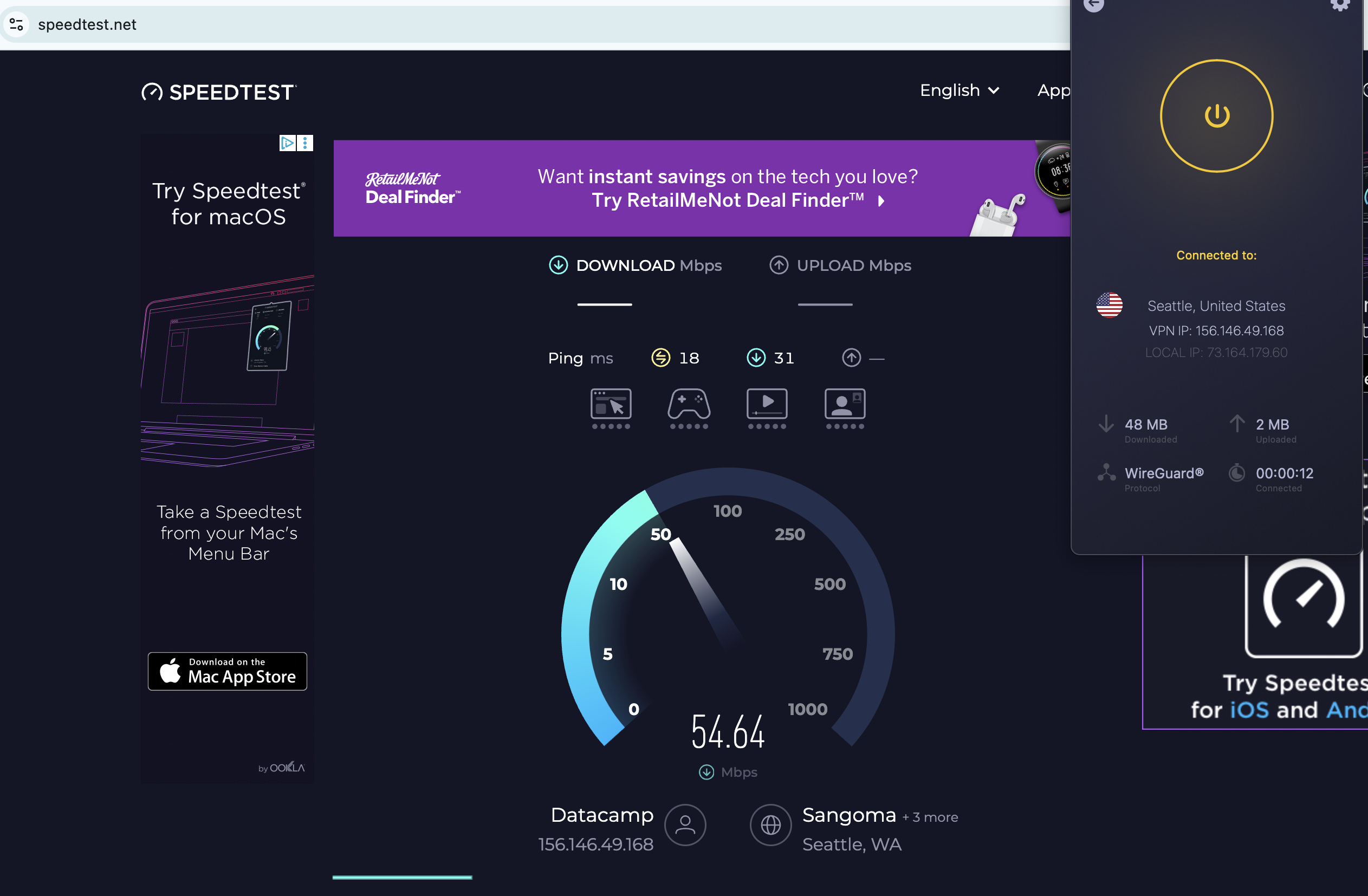
Windscribe speed test
I used speedtest.net to test Windscribe's speeds. In case you aren't familiar with the jargon, Ping measures a server's latency, which is how long it takes a single packet of data to reach it from your device. Download speed measures how much data can be downloaded at a time, while upload speed shows how quickly you can send data to the network. Think of ping as your car's speed in miles per hour and download and upload speed as the amount of traffic on the road.
As usual, I used the WireGuard protocol to run these tests, since it's almost always the fastest. Starting with my unprotected speeds at home in Portland, I moved gradually farther away until I was connecting to the other side of the world. Ideally, ping should increase linearly (not exponentially), while download and upload speeds don't dip much at all. I've recorded Windscribe's performance in the table below.
Server location
Ping (ms)
Increase factor
Download speed (Mbps)
Percentage drop
Upload speed (Mbps)
Percentage drop
Portland, USA (unprotected)
22
—
59.35
—
5.92
—
Vancouver, Canada (fastest location)
27
1.2x
55.89
5.83
5.56
6.08
Boston, USA
161
7.3x
48.49
18.30
5.66
4.39
Quito, Ecuador
283
12.9x
46.46
21.72
4.68
20.95
London, UK
287
13.0x
43.70
26.37
4.51
23.82
Nairobi, Kenya
595
27.0x
32.63
45.02
3.57
39.70
Seoul, South Korea
258
11.7x
43.27
27.09
4.48
24.32
Average
269
12.2x
45.07
24.06
4.74
19.93
Windscribe gave me some of the shortest latencies I've ever seen — comparable to CyberGhost, whose ping lengths I was also very impressed by. Its download and upload speeds also look a lot like CyberGhost's, with both firmly in good-but-not-amazing territory.
However, Windscribe's speeds were a lot more consistent. Throughout the tests, I hardly ever saw major fluctuations in the same location, on any metric. The Nairobi server seemed to be under some strain, but that's not unusual for a VPN in Africa. Every location except for that one followed a smooth downward curve. I'm happy with that; speed is one of the areas where you want your VPN to be reliably boring, not flashy.
Practically, a speed test like this suggests that Windscribe is best for gaming, livestreaming and video chatting, and that it's perfectly serviceable for any other task you could do online. You may not get the best speeds you've ever seen, but unless your internet is bad to begin with, Windscribe should not slow it down enough to be noticeable.
Windscribe security test
I can say up top that Windscribe doesn't seem to have any dangerous security flaws, but I'll take this section to explain why I think that. To start with, it uses only the three VPN protocols currently known to be secure: WireGuard, OpenVPN and IKEv2, plus a few other options all based on OpenVPN. With those options, you can be sure you're getting encryption that's currently uncrackable.
It also passed two batteries of tests I ran on its security. The first set of tests looks for DNS leaks, WebRTC leaks and other slip-ups that might reveal your real IP address. The second checks whether data packets sent through the VPN tunnel are actually getting encrypted. Check each section below for details on how Windscribe did.
VPN protocols
A VPN protocol determines how exactly a VPN makes contact between its own servers, your device and your ISP. Certain protocols can make your VPN run faster, stabilize a shaky connection or get into websites other protocols fail to unlock. If you're having a problem with your VPN, changing the protocol is one of the first troubleshooting steps.
Windscribe makes a total of six protocols available, though it's really just three, since four of the six are variations on OpenVPN. WireGuard works on every platform, and is currently the fastest and most stable — its drawback used to be that it was new, but with the passage of time, it's no longer new enough to make it suspect.
IKEv2 is a connection protocol that uses the separate IPSec protocol for its security. This double team's main strength is reconnecting to the VPN when a device switches networks; it's also good at not draining phone batteries. Windscribe supports IKEv2 on Mac, iOS and Windows.
OpenVPN is the oldest open-source VPN protocol, refined by over a decade of repeated probing by volunteers. It's not only relatively fast and highly secure, but comes in two flavors: TCP, which makes connections more stable, and UDP, which is usually faster and should be your first resort with OpenVPN. Windscribe supports OpenVPN on all platforms.
Windscribe rounds out the selection with two unique protocols, both focused on hiding your VPN traffic from firewalls and censors. Stealth uses the same connection ports as HTTPS, so it can't be blocked by shutting certain ports down entirely. WStunnel obfuscates connections even further by using the extremely common WebSocket technology to establish VPN connections. Both these proprietary protocols are much slower than the other options, but can save you if you find yourself repeatedly blocked while using Windscribe.
Leak test
I started my leak tests by using ipleak.net to check several Windscribe servers for IP leaks of all sorts. Each time I connected and checked my location, I only saw the VPN server's IP address, never my real one. I tried to trip Windscribe up by switching servers while remaining connected, even changing continents, but my true location never once slipped out. This puts its security solidly above CyberGhost, Norton VPN and many others.
I couldn't find any holes in Windscribe's armor.
Sam Chapman for Engadget
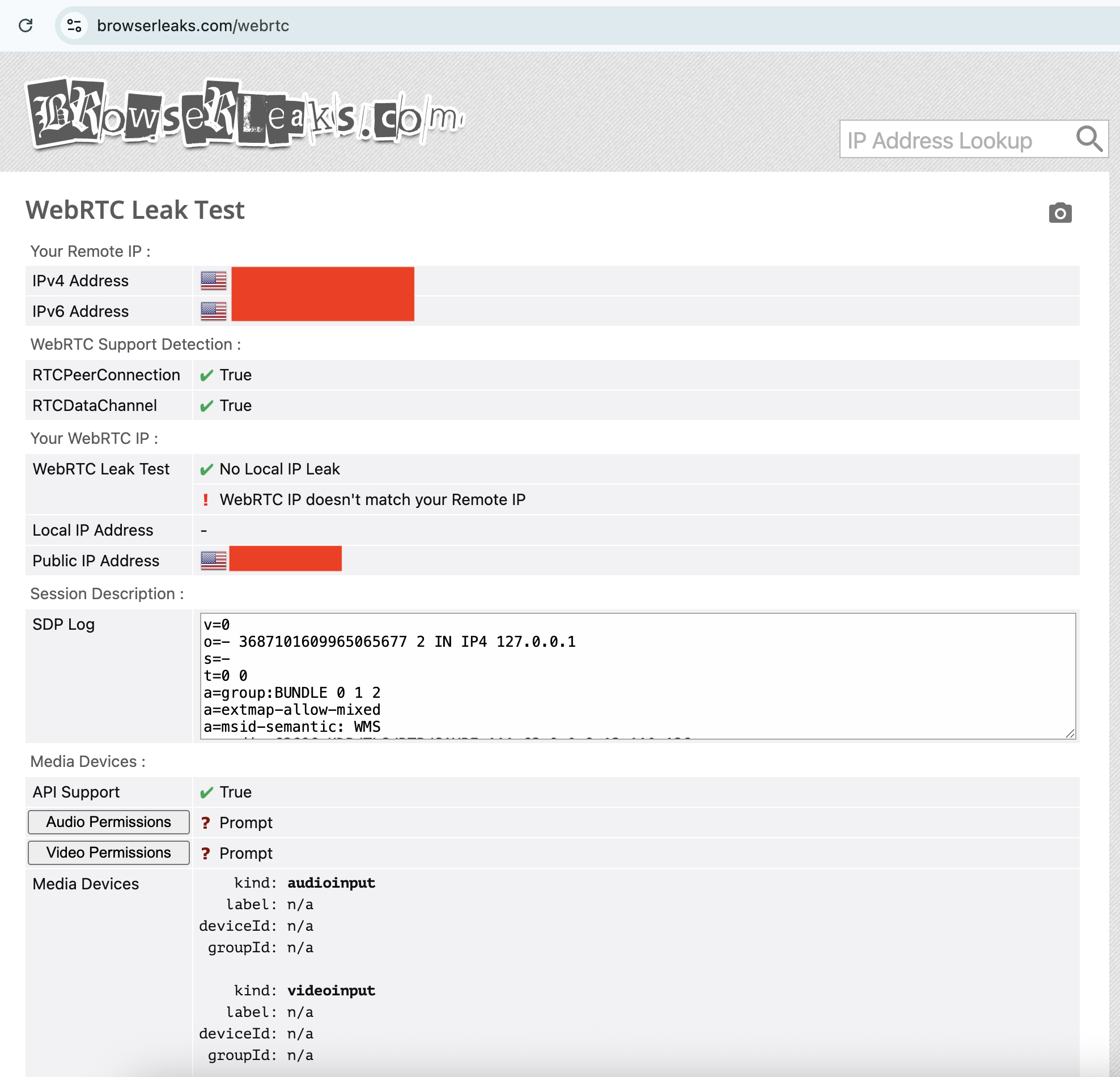
Windscribe automatically blocks IPv6 traffic while connected, so IPv6 leaks weren't going to be a thing. I finished the test by checking five servers using browserleaks.com/webrtc, finding no issues each time.
Encryption test
The final step is to make sure Windscribe is applying encryption properly through its VPN protocols. For this test, I used a free packet sniffer app called Wireshark to look directly at what my computer was sending out.
Windscribe's encryption looks solid.
Sam Chapman for Engadget
It's a bit hard to tell what's going on, but to summarize, I've loaded a website without HTTPS protection and checked whether Windscribe managed to apply that protection. The lack of readable information in the data stream proves that its encryption is indeed working as expected.
How much does Windscribe cost?
Windscribe has three subscription options (not counting its free plan, which I'll discuss in a moment). One month of Pro service costs $9.00 — after Mullvad, the second-cheapest monthly subscription to a top-tier VPN. You can also pay $69 for a 12-month Pro subscription, working out to $5.75 per month. Both of these tiers give you the exact same set of Pro features and can be used on unlimited simultaneous devices.
The cost of Windscribe Pro at publication time.
Sam Chapman for Engadget
The third option is to build your own plan. Build-A-Plan is an interesting beast that's unique to Windscribe. When you choose a custom plan, you must spend at least $3 per month. Gaining access to all the Pro servers in a country costs $1. For each country you add, you get an additional 10GB of data per month on top of the 10GB already included for free.
If you'd rather not budget your data at all, you can pay another $1 for unlimited data, plus 10 custom rules for the R.O.B.E.R.T. content blocker (I'll untangle the tortured acronym soon). It's a little convoluted, but wonderfully flexible. You can even change your Build-A-Plan in the middle of the subscription period.
Windscribe also offers shared static IPs for an extra fee. You can add a datacenter IP to any plan for $2 per month or a residential IP (usually better at getting around restrictions) for $8 per month. Team billing is also available through ScribeForce at $3 per seat per month, including a centralized management panel.
The Windscribe free plan
Windscribe isn't the overall best free VPN — hide.me wins that honor with its more flexible data limit — but it's close. Free users get access to servers in 10 countries: the US, Canada, the UK, the Netherlands, Norway, France, Germany, Switzerland, Romania and Hong Kong. If you plot that on a map, you'll see that the Windscribe free plan is most useful in North America and Europe.
Free users start with a data allotment of 2GB per month. The monthly limit rises to 10GB if you sign up with a confirmed email address and 15GB if you post about Windscribe on Twitter/X. That's enough for casual browsing, but streaming in standard definition takes about 1GB per hour, so you won't be doing much binge-watching.
On the upside, a free plan gives you access to all Windscribe's features except for dynamic port forwarding. You can set three R.O.B.E.R.T. rules and use your free account on an infinite number of devices (subject to the usual restrictions about exploiting that for commercial purposes — as Windscribe itself states, no one person has 30 devices that need a VPN).
Windscribe side apps and bundles
Windscribe doesn't have any add-ons of its own except for static IP addresses. However, it does offer discount codes for a group of "partners in privacy" that share its business ethics. The coupon codes are available here and don't require a Windscribe subscription to use.
The five members of Windscribe's gang.
Sam Chapman for Engadget
There are currently five allies in the gang. Control D offers DNS filtering for organizations to block unwanted websites; the Windscribe coupon gives you 50 percent off. You can get 25 percent off a one-year subscription to addy.io, an open-source email anonymizer, and Ente, an encrypted storage space for photos and videos.
Rounding out the team are Kagi,a private search engine which you can use for three months free with the Windscribe coupon, and Notesnook, an encrypted notes app. Windscribe's coupon gives you a 10% discount on Notesnook's yearly plans in perpetuity.
Close-reading Windscribe's privacy policy
Windscribe's marketing positions it as serious about user independence, so I came into this section hoping for a privacy policy that backs those words up. An early green flag is that the policy is short, succinct and obviously written to be read by the users themselves. It's also fantastic that you can sign up without an email address (though you will need one to get the full data allotment on the free plan).
Windscribe gathers information on its website using Piwik, an open-source analytics tool that it manages itself; no third parties are involved. The Windscribe app itself collects no information except for the amount of data used in a month, the time of your last connection and the number of devices you have online at once. When actively connected, it also gives you an anonymized username necessary for the OpenVPN and IKEv2 protocols.
My only quibble is that Windscribe is oddly reluctant to identify which third-party payment processors it uses. The information does exist elsewhere — an article in the knowledgebase states that payments are handled by "trusted third party processors such as PayPal and Stripe," and another page says that CoinPayments handles cryptocurrency transactions. It's a small thing, but the rest of the policy is so airtight that it stands out.
Independent privacy audits
Windscribe's apps are fully open-source (you can find them on Github here). In addition to this general exposure, it's also undergone three intensive audits from security firms. Leviathan Security looked into its desktop apps in 2021 and its mobile apps in 2022. The auditors made a total of five high-severity recommendations, all of which Windscribe claims to have addressed.
More recently, Windscribe had its entire codebase audited by PacketLabs. The auditors' June 2024 report found that some of Windscribe's code was storing more user information than it strictly needed to. Windscribe also claims to have handled this risk. More importantly, PacketLabs found no intentional subversions of Windscribe's no-logs policy, so its privacy statements can likely be trusted.
Further corroboration of the latter came from a 2025 court case in which Windscribe founder and CEO Yegor Sak was indicted in Greece and charged with a crime committed by a Windscribe user through an IP address in Finland. This case is obviously absurd — like charging the head of GM with a single instance of vehicular manslaughter committed by someone driving a Buick — but Sak was obliged to appear in court anyway.
As Sak writes in the linked post, he could have turned over the logs and shown who actually committed the crime, but he couldn't since Windscribe doesn't keep that information. Had there been an alternative to waging an expensive and inconvenient legal campaign in another country, Sak would surely have taken it. The fact that he didn't is strong proof of Windscribe's no-logging policy.
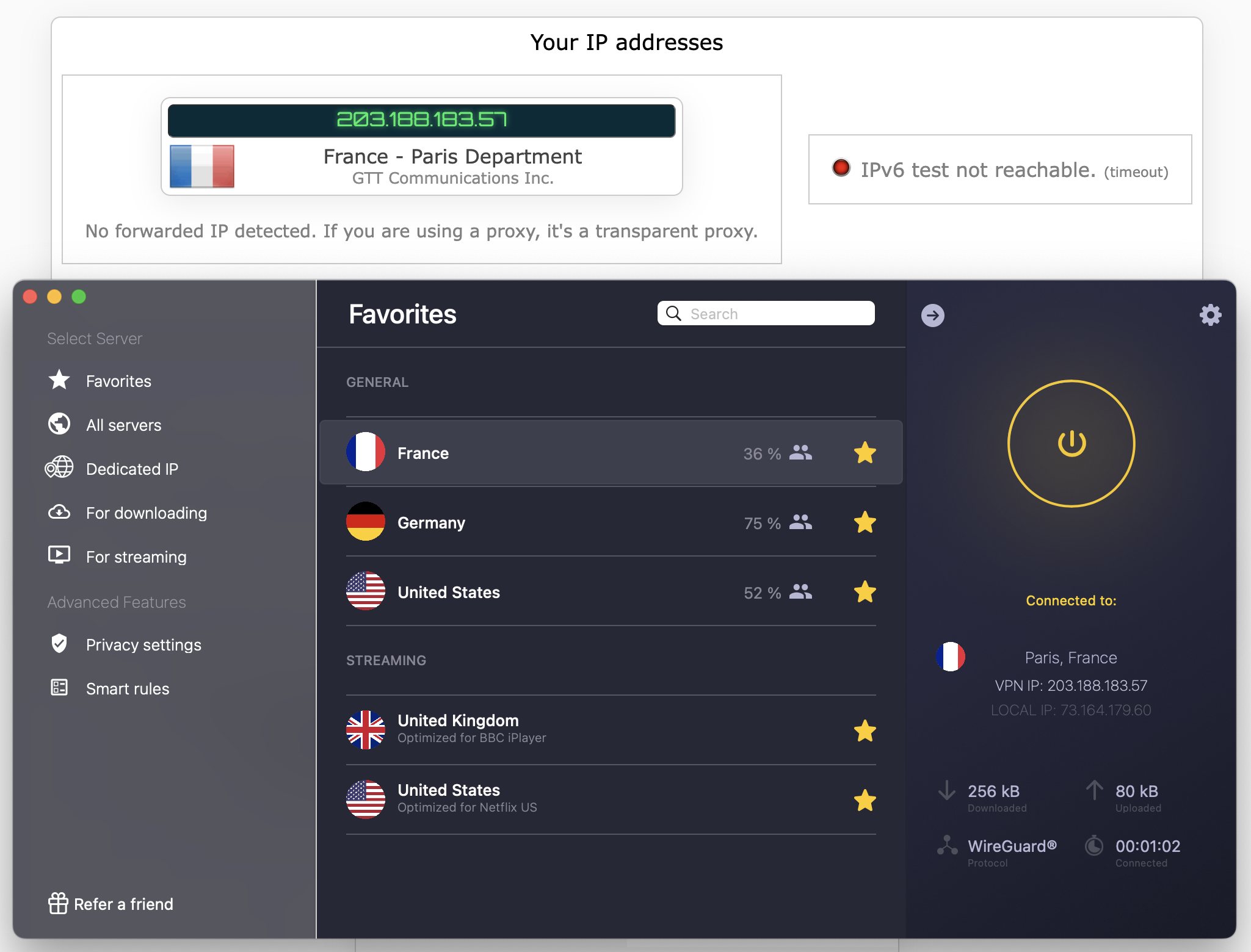
Can Windscribe change your virtual location?
Changing your IP address with a VPN can do more than just anonymize your internet activity. A service like Windscribe can give you an IP address associated with a certain country or region, letting you use the internet like you were there. This has applications ranging from the serious (break out of a nationwide firewall to document human rights issues) to the fun (get new titles on streaming platforms without paying for a new subscription).
Netflix is a great tool for testing whether a VPN can change your virtual location. Like most streamers, it tries to block all VPN access to protect the copyrights it holds. Consequently, if a VPN can crack Netflix, it must be serious about keeping its server network fresh to foil any potential blockers.
A successful location change on Netflix using Windscribe.
Sam Chapman for Engadget
For this test, I tried to access Netflix three times each through five different Windscribe server locations, refreshing the connection to use different servers each time. I looked for successful Netflix access, plus different content to prove my location had actually changed.
Server location
Unblocked Netflix?
Changed content?
Vancouver, Canada
3/3
3/3
Queretaro, Mexico
3/3
3/3
Tokyo, Japan
3/3
3/3
London, UK
3/3
3/3
Auckland, NZ
3/3
3/3
Windscribe got a perfect score. Netflix loaded easily every time, and the content was always localized to the country I chose. With this performance combined with its fairly consistent speeds over long distances, Windscribe makes a nearly perfect streaming VPN. The only downside is that the data limits on the free plan mean you'll probably have to pay for serious streaming time.
Investigating Windscribe's server network
Windscribe has 193 server locations in 71 countries, which it insists on listing as "69+" (again, hilarious). Although 193 sounds like a lot, many of them are duplicate locations in the same city. This isn't necessarily a problem, but for accuracy's sake, the total number of cities with Windscribe servers is 122.
Region
Countries with servers
Cities with servers
Total server locations
Virtual server locations
North America
6
40
61
0
South America
7
7
9
0
Europe
38
47
75
0
Africa
3
3
5
0
Middle East
2
2
2
0
Asia
12
16
28
1
Oceania
2
6
12
0
Antarctica
1
1
1
1
Total
71
122
193
2 (1 percent)
The bigger story here is Windscribe's spurning of virtual servers. A virtual server location is physically located in a different region than the one it outwardly displays. For example, a server with an Indian IP address might really be in Singapore. Throughout the entire Windscribe network, only two servers are virtual: one in India and one in Antarctica.
This is both good and bad. On the positive side, the near-total lack of virtual servers means you can be sure of how any server will perform. If it says it's in Buenos Aires, it'll run like it's in Buenos Aires — you won't be surprised with lagging speeds because it's really in Miami. This also makes it clear that Windscribe isn't interested in pumping up its network size for marketing purposes.
Windscribe's server selection list on the Mac app.
Sam Chapman for Engadget
On the other hand, virtual locations aren't an inherently bad thing. Windscribe acts as though advertising hype is the only reason any VPN would employ them, but there are real use cases. Virtual servers can be used to place locations inside countries where real servers would risk confiscation by the government, like Russia, India and China. Windscribe chooses instead to place real servers in Russia and India, both of which have data retention laws that directly conflict with its own privacy policy.
Does this mean that using Windscribe's Russian servers will earn you a midnight visit from the FSB? Probably not. Assuming Windscribe is following its no-logs policy (which appears to be the case), there won't be any user data on those servers if the government seizes them. But it does mean they're effectively running illegal data centers which could be raided and shut down at any time. Be aware of this if you depend on Windscribe's locations in Russia or India.
Extra features of Windscribe
As covered in the UI section, Windscribe has a lot going on in its apps. The Connection tab alone has 13 different features, including two submenus with several options of their own. With this many options, and so many of them highly situational, I won't be able to cover every nook and cranny without this review getting seriously bloated. I've instead chosen some of the most important and illustrative features to give you a clear sense of the whole picture.
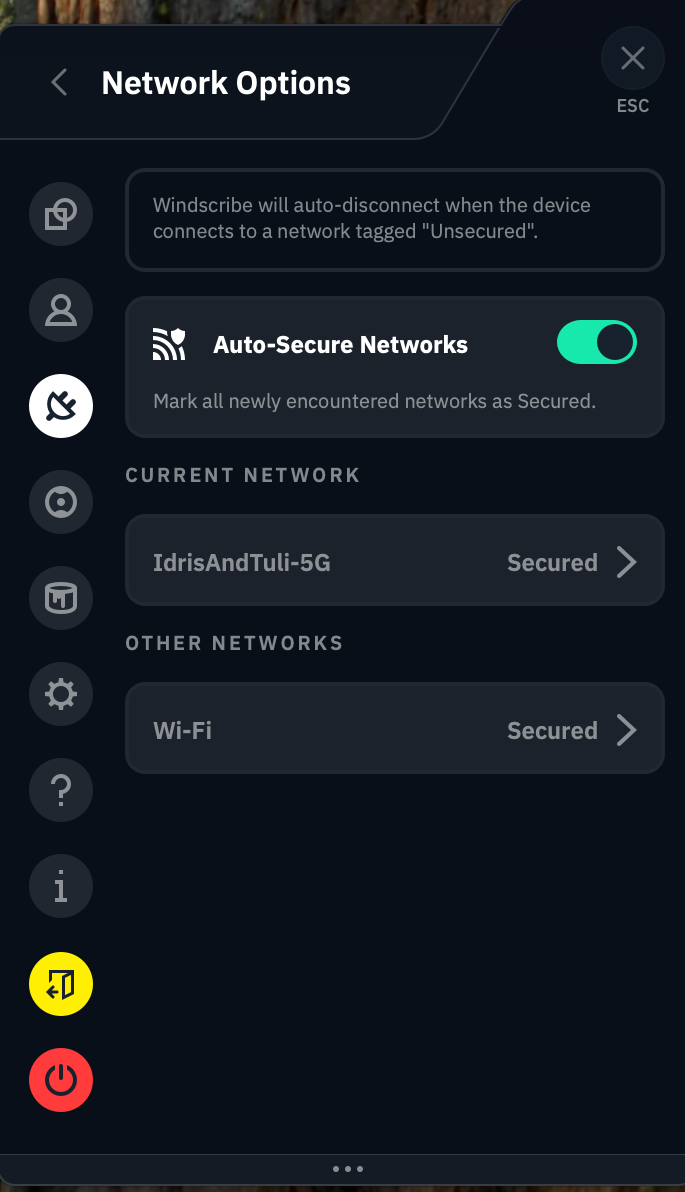
Network Options
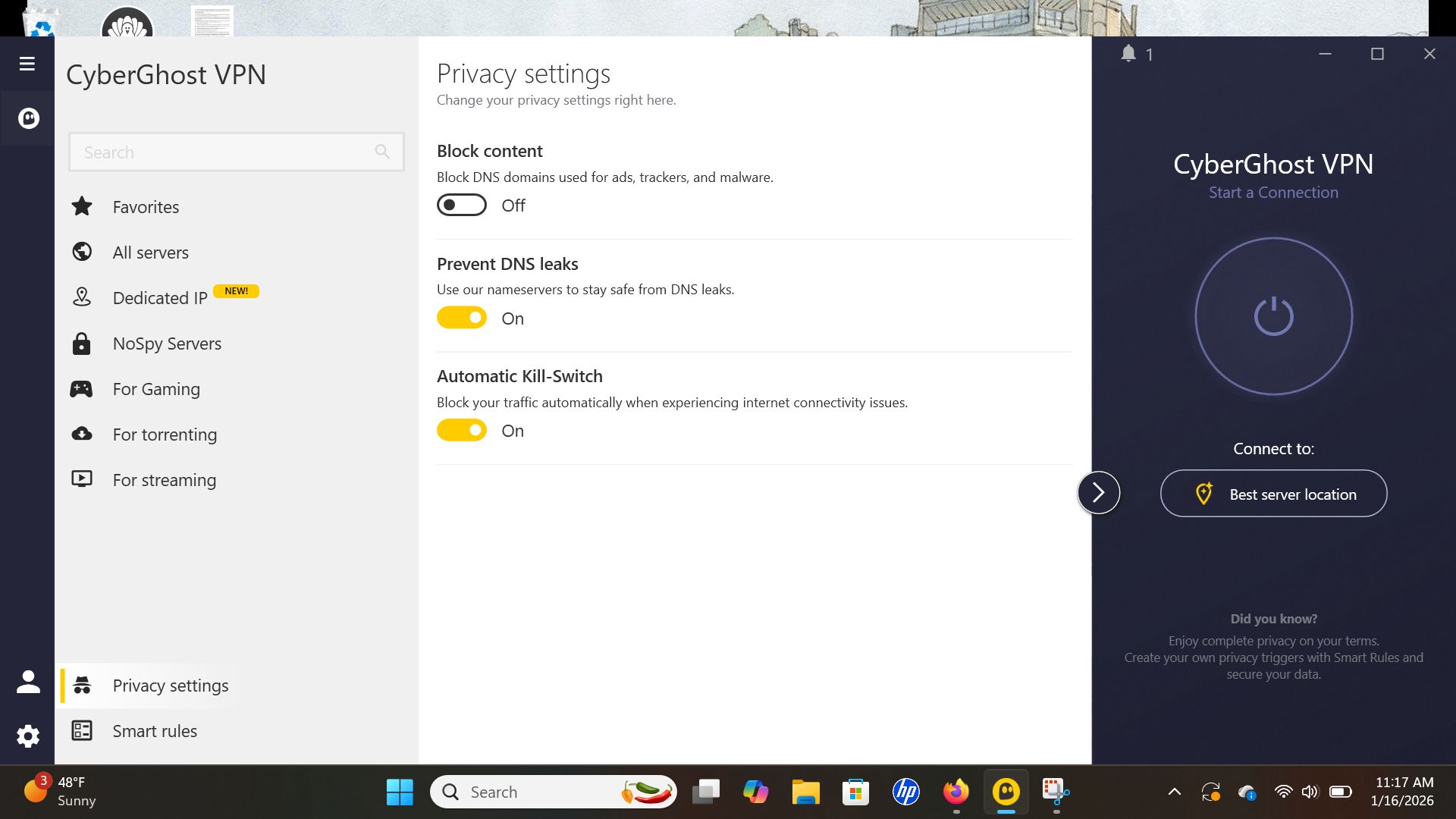
You'll find this feature at the top of the Connection tab. When you click Network Options, you should see the name of your current Wi-Fi network and all the others your Windscribe account has discovered. This feature lets you control how the VPN reacts to each network it encounters, not unlike CyberGhost's Smart Rules.
Just switching around a few terms would make this a lot less confusing.
Sam Chapman for Engadget
The app does a remarkably poor job of explaining how this works, so I'll break it down for you here. When the Auto-Secure Networks switch is turned on, Windscribe will automatically mark each new network as Secured — a word which here means "Windscribe turns on when it encounters the network."
So far, so good. But if you turn Auto-Secure Networks off, things get weird. Without it, Windscribe tags every network you encounter as Unsecured. Whenever you connect to an Unsecured network, Windscribe immediately disconnects itself. This means it secures all Secured networks and does not secure any Unsecured networks.
It feels backwards until you realize that Windscribe is referring entirely to itself here. "Secured" doesn't mean that the Wi-Fi network is password-protected or otherwise considered safe, and "Unsecured" doesn't mean that it's open to the public without a password. All that matters is whether or not you want Windscribe to activate or deactivate on that network. It's a useful feature that even lets you choose a VPN protocol for each network, but it would help to bring it more in line with mainstream terminology.
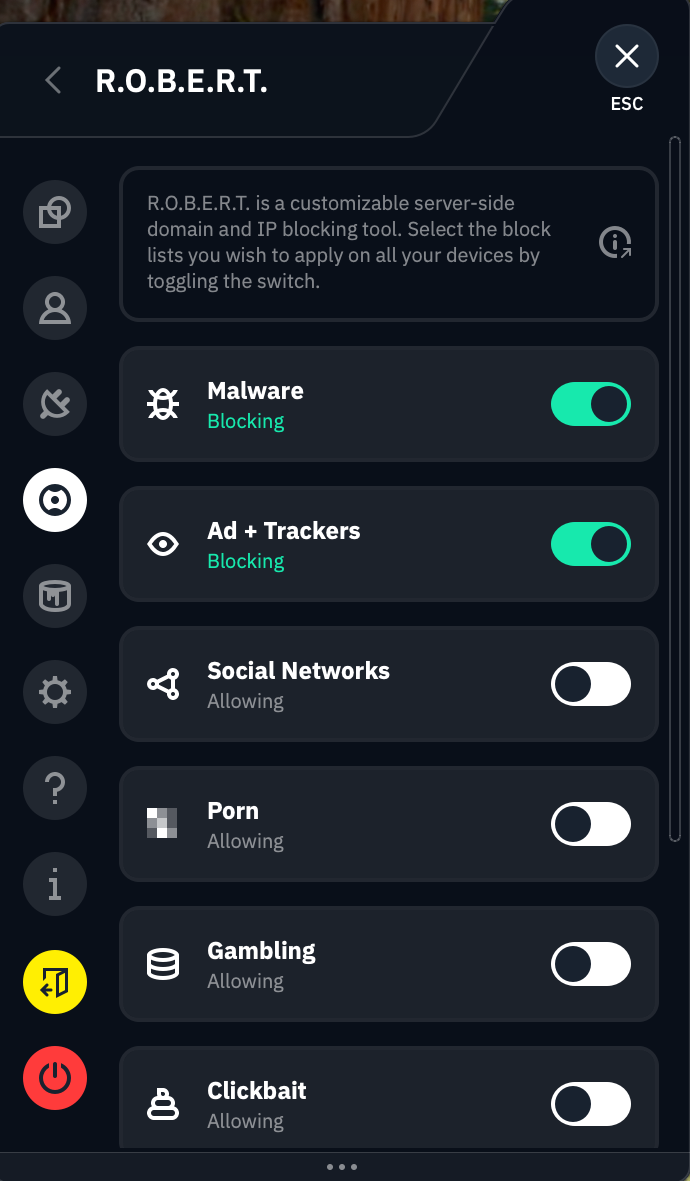
R.O.B.E.R.T.
This mouthful of a feature name allegedly stands for Remote Omnidirectional Badware Eliminating Robotic Tool. This is perhaps the apex of the VPN industry's unfortunate habit of saddling perfectly good features with word-salad names (yes, I'm aware it's supposed to be funny).
R.O.B.E.R.T. is perhaps the most customizable content blocker on any VPN right now. To start with, it includes eight lists of sites it blocks at the DNS level: Malware, Ad + Trackers, Social Networks, Porn, Gambling, Clickbait, Other VPNs and Crypto. These vary in usefulness, and you can't determine the contents of each list, but it's nice to have such a range of choices.
It eliminates all the badware, remotely AND omnidirectionally!
Sam Chapman for Engadget
Where R.O.B.E.R.T really shines, though, is in its browser-based customization dashboard. Each Free user can make three custom rules, and Pro upgrades that to 10. Each custom rule can be used to block a specific website or network or allowlist it from one of the other general blocklists. You can also set it to spoof a domain, though there's no practical reason to do this (Windscribe's idea of a "useful" application is making your friends think your post made the front page of Reddit).
Split tunneling
Split tunneling sends some of your internet requests through the VPN tunnel while others go unencrypted as normal. This can be useful if you get worse-than-usual speeds and want to minimize the amount of traffic going through the VPN, or for certain websites that refuse to work with any VPN server.
You can split tunnel on Windscribe's apps for Windows, Mac and Android. Windows and Android users can split by app or website, while Mac users can only split by website. Windscribe lets you choose whether your split tunnel will be inclusive (only apps and IPs on the list will go through the VPN) or exclusive (the apps and IPs on the list will not go through the VPN). Note that R.O.B.E.R.T. rules apply to the entire system, even excluded apps and domains.
Firewall and Always On VPN
Instead of a kill switch, which it derides as an incomplete solution, Windscribe includes a Firewall feature on desktop and an Always On VPN feature on mobile. The Firewall can be considered a strong kill switch that prevents any internet traffic from going outside the VPN tunnel — something doesn't have to go wrong for the blocks to activate. Always On VPN on iOS and Android is functionally the same.
A more proactive defense has its advantages, but it would be nice if Windscribe included the weak kill switch option. Kill switches and firewalls can be overactive, and sometimes, you don't want the strongest level of security.
Circumvent Censorship
This feature is designed to let you access Windscribe on networks that don't want you to use a VPN, from school and work systems to entire censorious countries like China. Windscribe isn't forthcoming about how it works, but it's probably a deep-packet obfuscation that makes VPN traffic look like regular traffic. I didn't have time to pop over to China and test Circumvent Censorship, but I'm glad it exists.
Windscribe customer support options
Clicking the question mark tab on the Windscribe app shows you the full list of support options. You can peruse the knowledgebase, ask their chatbot Garry, talk directly to a human or check out their user communities on Reddit and Discord.
Most of these lead back to Garry.
Sam Chapman for Engadget
I started with the written FAQs. At the top of the knowledgebase, there's a row of buttons you can click to see only articles relating to a particular operating system. This is a good idea in theory, but it's not implemented very well — there's no visible tagging system, so we can't see how it's deciding which articles to filter.
The search bar is much more likely to get you where you need to go. It works instantaneously and always turns up relevant articles, though it's weirdly insistent on showing exactly 10 results. I have few complaints about articles themselves, which are written in a way any user should find useful (give or take yet more attempted humor).
I tested the chatbot, Garry, by asking it about the mysterious Advanced Parameters tab of the Windscribe app. It explained each feature on that tab (none of which should be touched except by users with technical knowledge) in a spiel that was clearly pre-written but nonetheless useful. Garry was launched in 2018, when IBM Watson was the biggest thing in AI, and recently revamped into "Garry 2.0" — whether this is based on OpenAI or another platform is anyone's guess at the moment.
Live support
Windscribe appears to handle all of its own support, without outsourcing to Zendesk or a similar third party. If you decide not to go through Garry, Windscribe does have the option of connecting directly to a human. However, the Contact Humans option on the app sends you directly back to Garry. It's eventually possible to get Garry to connect you to a real person, but that doesn't excuse Windscribe building an outright lie into its app.
The Contact Support button on the knowledgebase, which I expected to lead to a ticket submission, also sends you straight to Garry. Windscribe really, really wants you to use Garry, in case that wasn't clear. You might have a better time going straight to the Windscribe Discord server or the r/Windscribe subreddit, both of which are linked to in the app.
Windscribe background check
Windscribe eschews a lot of the things we've come to expect from a VPN provider. It doesn't pay for ads anywhere. It has no affiliate relationships with news sites. The only thing resembling a Windscribe ad campaign is the free-plan data reward for Xeeting about it. It doesn't even have any venture capital investors — it's completely self-funded and self-hosted.
As a jaded and cynical reviewer who was already annoyed by Windscribe's memelord attitude, I was prepared to sniff out any hypocrisy in its background, which makes it all the more impressive that I didn't find any. Since its founding in Canada in 2016, Windscribe has never once been involved in any public doings that contradict its statements of ethics. It's even given free unlimited VPN access to every journalist working in Ukraine.
The only thing I could find resembling a controversy was an incident in July 2021 when Ukrainian police confiscated two servers that weren't fully encrypted. Although this would only have posed a risk to users running a customized connection profile under very specific conditions, it was still a lapse. Windscribe responded appropriately in my view, ending the legacy OpenVPN implementation that caused the problem.
Canadian headquarters
Windscribe is based in Canada, which is one of the Five Eyes nations (along with the U.S., the U.K., Australia and New Zealand). This sounds scary, but it's not actually an issue, as Yegor Sak himself points out in a blog post I reference frequently.
Five Eyes is not an organization, but an agreement between five allied countries to share necessary intelligence with each other. This can absolutely be misused. If the U.S. government wants to spy on someone without running into the 4th Amendment, it can ask the Brits to spy on that person instead and tell them what they find, knowing the Constitution can't determine what other countries do to our citizens.
As bad as that is for our civil liberties, it doesn't actually change anything where VPNs are concerned. If a VPN isn't logging user data, there shouldn't be anything for any of the Five Eyes (or Nine Eyes or Fourteen Eyes) nations to find. And if it is keeping logs, you shouldn't be using it no matter where its headquarters are.
Final verdict
You might wonder, at this point, why my distaste for Windscribe's tryhard sense of humor has featured so prominently in this review. One reason is that I had to read a lot of it this week, and you must suffer as I have suffered. But it also makes Windscribe look very good by implication. Having no patience for the discount-4chan act that pervades Windscribe's brand, I was primed to dislike the VPN itself — and I simply couldn't.
This is not to say I had no problems at all with Windscribe. Its physical servers in Russia are difficult to trust. Its help options lean way too heavily on Garry the chatbot. Its app design and UI writing are significant faults. The free plan doesn't give you enough data for streaming.
Having said all that, though, Windscribe does everything else right. It changes virtual locations and unblocks Netflix without breaking a sweat. Its servers keep latencies low, and download speeds remain solid across the world. The apps may look bad, but they never break down. Some features, like R.O.B.E.R.T. and Auto-Secure, are both useful to everybody and deeply customizable for power users.
Windscribe may be best for privacy nerds who know how all its doohickeys work, but it's a VPN I recommend for everybody. In a world of predatory software, it's a relief to use an app that's unabashedly on the customer's side.
This article originally appeared on Engadget at https://www.engadget.com/cybersecurity/vpn/windscribe-review-despite-the-annoyances-it-has-the-right-idea-120000837.html?src=rss
Pornhub will stop offering full access to new users in the UK on February 2, its parent company Aylo said Tuesday, citing the nation's Online Safety Act and its age-verification requirements. The company said users who already verified their ages before the cutoff will still be able to access the adult site through existing accounts.
The move follows the Online Safety Act’s Protection of Children Codes, which took effect last summer and require adult sites to use "highly effective" methods of age verification. Aylo claims the system is backfiring and shifting both adults and minors to noncompliant porn sites that don’t verify age or moderate content according to Politico. Aylo's lawyers argued that only device-based age verification methods sufficiently protect user data.
Alexzandra Kekesi, VP of Brand and Community at Aylo, said "anyone who has not gone through that process prior to February 2 will no longer be able to access [the sites] and they're going to be met with a wall," according to 404 Media. The adult site was similarly made unavailable in various US states after the passage of age-verification laws that Pornhub claimed put users' privacy at risk. "These people did not stop looking for porn," Aylo said at the time. "They just migrated to darker corners of the internet that don’t ask users to verify age, that don’t follow the law, that don’t take user safety seriously, and that often don’t even moderate content."
Users who wish to get around these sorts of bans typically use VPNs to mask the origin of their internet traffic, though the UK is reportedly considering a ban on VPNs for children. The nation has also been considering a social media ban for users under 16 years of age, similar to the one enacted in Australia.
This article originally appeared on Engadget at https://www.engadget.com/entertainment/pornhub-will-become-unavailable-for-many-uk-users-as-of-february-2-194622124.html?src=rss
Meta's WhatsApp just introduced something called Strict Account Settings, a tool "that further protects your account from highly sophisticated cyber attacks." This is a one-click button in the settings that automatically initiates a series of defenses.
So what does it do? It blocks media and attachments from unknown senders, disables link previews and silences calls from unknown senders. This results in a more restrictive experience, but hopefully a safer one.
The company says this isn't necessarily for regular users, as conversations are already protected by end-to-end encryption. Instead, this is being pitched as a tool for "journalists or public-facing figures" that "may need extreme safeguards against rare and highly sophisticated cyberattacks."
Strict Account Settings will be rolling out globally in the coming weeks. Users will find the tool in the Privacy settings.
WhatsApp is just the latest tech platform to offer enhanced security tools for high-risk users. Apple introduced Lockdown Mode back in 2022 and Android introduced its Advanced Protection Mode last year.
This article originally appeared on Engadget at https://www.engadget.com/cybersecurity/whatsapp-introduces-an-advanced-security-mode-to-protect-against-hackers-174144598.html?src=rss
Your Gmail inbox should now be back to normal after Saturday’s hiccups. Google said in an update on X on Saturday night that the issue, which affected the automatic filters that keep Gmail users’ inboxes free from the clutter of promotional emails, non-urgent updates and spam, “is now fully resolved for all users.” On its Workspace status dashboard, it added that an investigation is underway, and an analysis will be published once complete.
Gmail users on Saturday reported that their inboxes were flooded with promotional emails that had not been properly sorted out of the main tab, and some said they were seeing notices that emails had not been scanned for spam. On social media and DownDetector, some Gmail users also reported delays in receiving messages, leading to issues with two-factor authentication logins. After confirming the issue, Google noted in an update on its Workspace dashboard that the problem resulted in the "misclassification of emails in their inbox and additional spam warnings," including a banner that says, “Be careful with this message. Gmail hasn't scanned this message for spam, unverified senders, or harmful software.”
In a statement to Engadget, a Google spokesperson echoed the message from its dashboard, saying, "We are actively working to resolve the issue. As always, we encourage users to follow standard best practices when engaging with messages from unknown senders."
Update, January 25 2026, 9:53AM ET: This story has been updated to reflect that the issue has been resolved.
This article originally appeared on Engadget at https://www.engadget.com/apps/google-says-its-working-to-fix-gmail-issue-thats-led-to-flooded-inboxes-and-increased-spam-warnings-183358654.html?src=rss
Meta will no longer allow teens to chat with its AI chatbot characters in their present form. The company announced Friday that it will be "temporarily pausing teens’ access to existing AI characters globally."
The pause comes months after Meta had said it was working on chatbot-focused parental controls following reports that some of Meta's character chatbots had engaged in sexual conversations and other alarming interactions with teens. Reuters reported on an internal Meta policy document that said the chatbots were permitted to have "sensual" conversations with underage users, language Meta later said was "erroneous and inconsistent with our policies." The company announced in August that it was re-training its character chatbots to add "guardrails as an extra precaution" that would prevent teens from discussing self harm, disordered eating and suicide.
Now, Meta says it will prevent teens from accessing any of its character chatbots until "the updated experience is ready." Those updates will include parental controls, according to a Meta spokesperson. The new restrictions, which will be starting "in the coming weeks," will apply to those with teen accounts, "as well as people who claim to be adults but who we suspect are teens based on our age prediction technology." Teens will still be able to access the official Meta AI chatbot, which the company says already has "age-appropriate protections in place."
Meta and other AI companies that make "companion" characters have faced increasing scrutiny over the safety risks these chatbots could pose to young people. The FTC and the Texas attorney general have both kicked off investigations into Meta and other companies in recent months. The issue of chatbots has also come up in the context of a safety lawsuit brought by New Mexico's attorney general. A trial is scheduled to start early next month; Meta's lawyers have attempted to exclude testimony related to the company's AI chatbots, Wired reported this week.
Correction, January 23, 2026, 11:18AM PT: This post was updated to clarify that Meta’s planned chatbot parental control features have not yet rolled out.
This article originally appeared on Engadget at https://www.engadget.com/social-media/meta-is-temporarily-pulling-teens-access-from-its-ai-chatbot-characters-180626052.html?src=rss
1Password has a new tool designed to counteract the advantages AI has given to phishing scammers. A new feature for the company's browser extension gives you a "second pair of eyes" to help you catch a bogus website before entering your login info.
Before AI, phishing attempts often included telltale signs like obvious typos or rudimentary graphic design. Now that AI makes it much easier to design and code convincingly, scams are on the rise. According to Fortune, 60 percent of companies reported an increase in fraud-related losses from 2024 to 2025. And the advent of AI browsers could make things even worse.
“Our new phishing feature adds an extra layer of protection,” 1Password says. Once the feature is activated, the extension actively watches for suspicious sign-ins. To be clear, even before this feature's arrival, 1Password wouldn't autofill saved credentials for a bogus website impersonating it. But that still left room for people to manually paste their login info, handing it over to those with the worst intentions.
That moment when you try to paste your login manually is where the new feature comes in. "The website you're on isn't linked to a login in 1Password," the feature's warning pop-up reads. "Make sure you trust this site before continuing."
1Password says that's the "breakthrough" moment that can help you avoid a major hassle. "That single moment of pause, that tiny bit of friction, is often all it takes to disrupt the attackers' entire plan."
The new feature is available today. You can enable it in the 1Password browser extension's settings. Under the Notifications section, activate the setting for "Warn about pasted logins on non-linked websites."
This article originally appeared on Engadget at https://www.engadget.com/cybersecurity/1password-adds-an-extra-layer-of-phishing-protection-140000293.html?src=rss
One of the disconcerting things about using a virtual private network (VPN) is that it can be hard to tell when it's doing its job. The best VPNs all work in the background to keep your IP address hidden and your communications with their servers encrypted. The better the VPN, the less you notice it, which can make a top-performing VPN feel (uncomfortably) like one that isn't working at all.
Luckily, you've got options for checking whether your VPN is working — other than just taking the app at its word. In this article, I'll cover the basics, then go through five different tests you can run to make sure you're actually using an encrypted VPN server. For each test, I'll explain what kind of problem it's looking for, how to run it and what to do in case it fails.
Make sure your VPN is turned on
Before you do anything else, though, it's not a bad idea to check your VPN app and make sure you remembered to connect. It's all too easy to open up the client app, choose a server, tweak some preferences and feel like your work is done. On top of that, we don't always remember to tell VPN beginners that simply opening the client isn't enough.
To check that your VPN is turned on, open the app on your desktop or mobile home screen. Each VPN designs its apps differently, but common signs include the color green, the word Connected and information on what server location you're connected to.
The main UI for Proton VPN, with the connection button visible at top-left and the server location menu below it.
Sam Chapman for Engadget
If you don't see anything like that, click the On button, which should be on the first page that appears when you log into the app. Most VPNs also connect whenever you click the name of a server location.
For those of you on iPhone or iPad, I've just written an explainer on how to turn a VPN off and on. For all the tests I'll discuss across the rest of this article, make sure you're connected to a VPN server before you run them. Also, make sure your internet connection is active — a VPN can only work when there's internet.
5 tests to check if your VPN works
Each of these tests investigates a different reason your VPN might not be working. We'll start by looking for connection problems that might not be obvious, check for DNS leaks, WebRTC leaks and IPv6 leaks, then finally make sure an apparently active VPN is managing to change your virtual location.
1. Has your IP address changed?
Websites and internet service providers (ISPs) use IP addresses to identify devices and their owners online. A VPN's most important job is to change your IP address to one matching its own server, which disassociates your identity from your online activities. Not doing this indicates a failure on a fundamental level: either the VPN says it's connected when it isn't, or its technology is active but somehow not sending you through the proper encrypted tunnel.
To check whether your VPN has changed your IP address, start by going to an IP address checker like whatismyipaddress.com or ipleak.net. This will show you the public IP address that everyone sees when you get online without a VPN, including the ISP that holds it and the geographic location it's associated with. Write that down or take a screenshot.
A censored report from WhatIsMyIPAddress.com.
Sam Chapman for Engadget
Next, connect to your VPN. Remember the location you connect to, and note down the new server IP address if the VPN tells you what it is. Go back to your IP tester tool and refresh the page. You should now see an IP address and location that match the one you connected to through the VPN, including a different ISP.
If your IP address is the same as before, your VPN isn't working. To fix this, try disconnecting from the server, waiting about 10 seconds, then connecting to the same location and trying the test again. This will show you whether the problem was with one individual server or an entire location.
If the problem persists, try a different server location, then a different VPN protocol. If it's still leaking, try restarting your VPN client, your device and your modem (in that order). This should fix the problem, but if it doesn't, move on to the remaining tests or get in touch with the VPN's tech support.
2. Are you leaking DNS requests?
A domain name system (DNS) server is an important step in getting a website to appear on your browser. DNS holds the information that connects URLs to the IP addresses of destination servers. If a VPN client lets your device contact a DNS server owned by your internet service provider without routing it through an encrypted tunnel first, the DNS request might reveal your real IP address to the ISP.
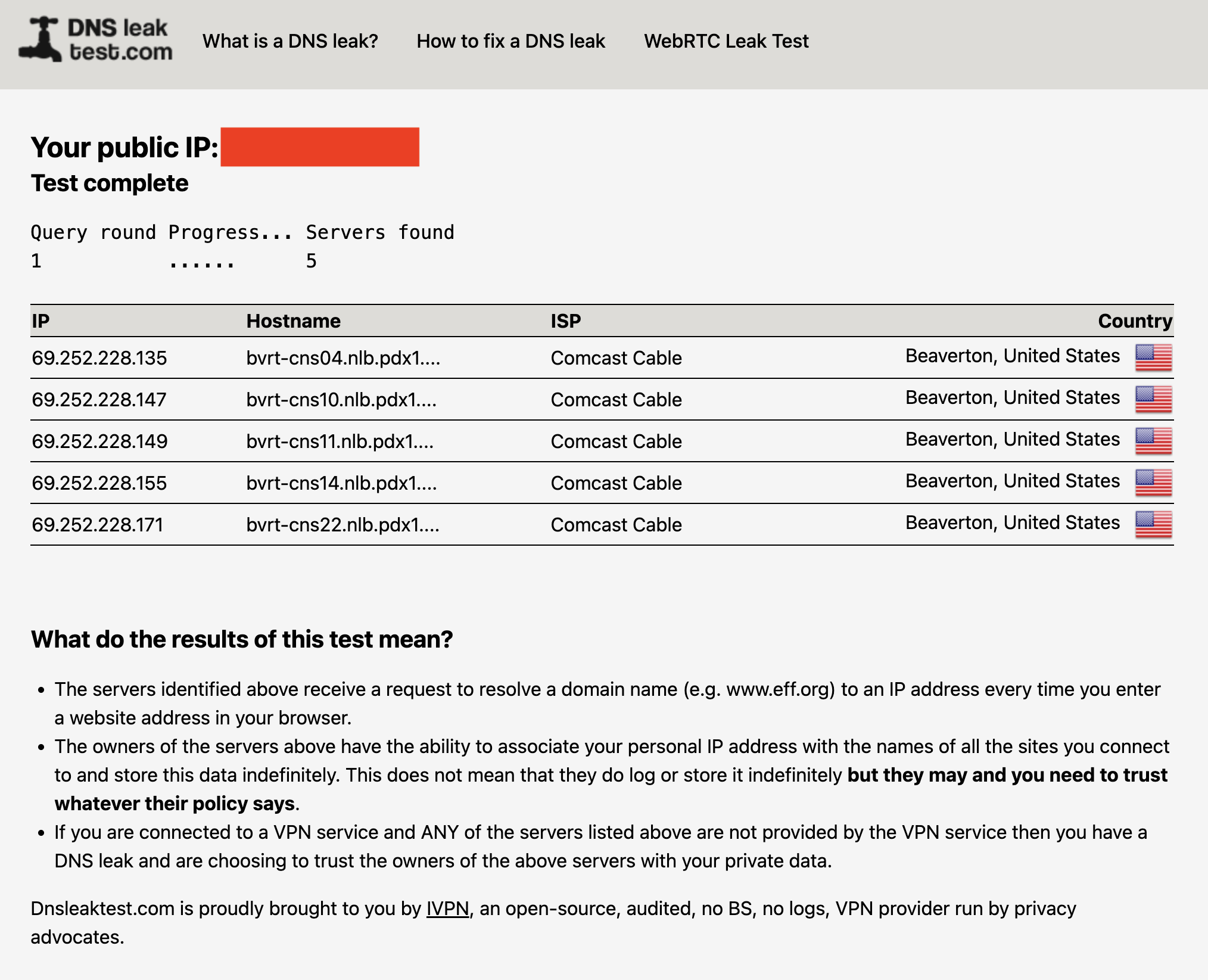
You can check for DNS leaks by connecting to your VPN, then going to dnsleaktest.com or another tool of your choice. The tester sends several innocuous DNS requests, then scans to see which servers resolve them. If you see your real ISP at all, you've got DNS leaks.
A DNS leak test run without a VPN. With one active, my real ISP (Comcast) should not appear on the list.
Sam Chapman for Engadget
The fix for DNS leaks is more intensive than the fixes in step #1. Check your VPN's control panel to activate any DNS leak protections and try again. IPv6 leaks can also appear as DNS leaks, so try disabling IPv6 in your browser (see #4 below for instructions). If you keep seeing leaks, you can also try clearing your computer's DNS cache.
Here's how to do that. On Windows, go to the Command Prompt (on Windows 10) or the WindowsTerminal (on Windows 11). Enter the phrase ipconfig/flushdns. On Mac, open Terminal from the Utilities folder, then paste in the phrase sudo dscacheutil -flushcache; sudo killall -HUP mDNSResponder and hit Enter. Test the VPN once more to see if it's still leaking.
3. Are you leaking information through WebRTC?
WebRTC, which stands for Web Real-Time Communication, is a technology that lets browsers exchange information directly with each other. This is useful for text and video chats, streaming and more, but it's also a potential security risk. WebRTC can serve as a backchannel that inadvertently sends your real IP address outside the VPN tunnel.
It's pretty easy to test for WebRTC leaks. I recommend the tool ipleak.net, which checks for them as a matter of course. You can also use browserleaks.com/webrtc to run a test that's particular to this kind of leak. These tools establish dummy connections through WebRTC, then test to see if the VPN still works when they're active. As usual, if you see your real IP address, there's a problem.
Your WebRTC IP not matching your Remote IP is a potential red flag.
Sam Chapman for Engadget
The fixes for a WebRTC leak are the usual ones: try different servers, locations and protocols, reset your VPN, device and modem, then try another VPN provider. However, if nothing is working, you can also disable WebRTC on your browser altogether. This means you won't be able to do any real-time chatting (that's Zoom, Google Meet, Teams and so on), so it's a last-resort solution.
To disable WebRTC on Firefox, type about:config in the URL bar, click the message to accept the risk, type media.peerconnection.enabled in the search bar, then double-click the word True to change it to False. To turn WebRTC back on, just double-click False again.
On Edge, you can disable WebRTC by entering edge://flags in the URL bar, scrolling down to the option "Anonymize local IPs exposed by WebRTC" and making sure the dropdown next to it is set to Enable. There's no built-in way to turn off WebRTC on Chrome, but you can install the WebRTC Control extension to switch it off and on yourself.
4. Is your IPv6 address leaking?
Next up, it's possible that your real location is leaking through your IPv6 address, not IPv4. To make a long explanation short, IPv6 is a new way of formatting IP addresses that leaves more options available for the future. Since we haven't yet hit the crisis point of IPv4 shortage, very few websites are restricted to IPv6 alone.
The problem is that most VPN apps were designed in the IPv4 era and aren't built to protect IPv6 traffic. There are some exceptions, including NordVPN, but most VPNs block IPv6 traffic completely rather than retrofit themselves to work with it. However, if a VPN of that sort isn't blocking IPv6 entirely, your IPv6 address and associated location can leak.
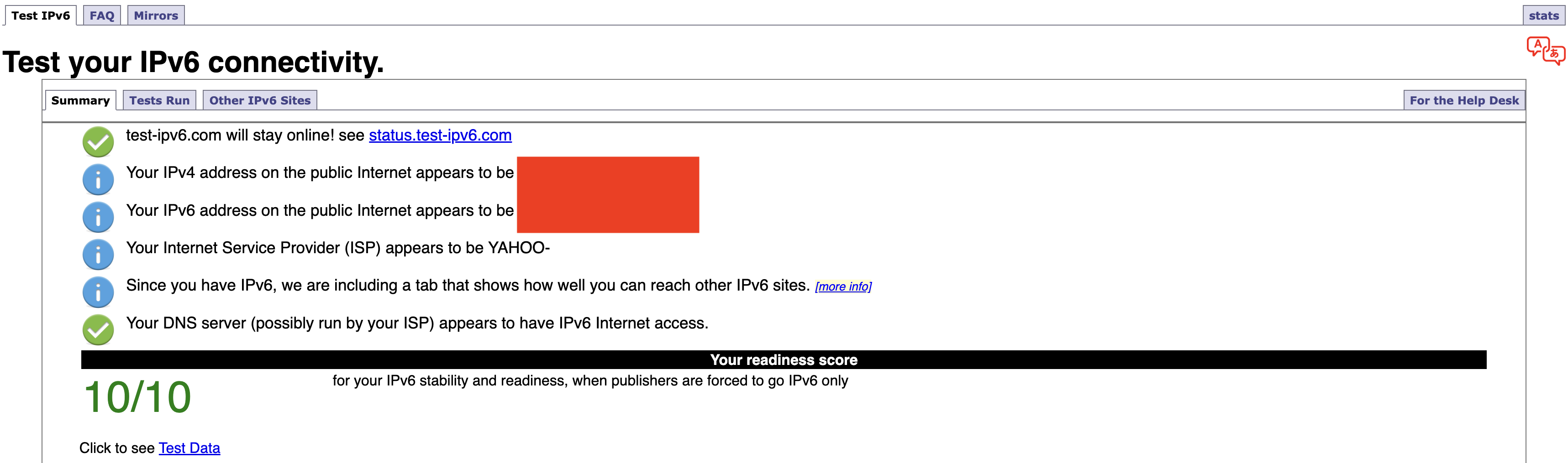
Any IP address checker can reveal an IPv6 leak, but you can find a specific test at test-ipv6.com. This site runs several exams that look for IPv6 readiness, but the most important line is the one that shows your current IPv6 address. This will probably say you don't have one, since most ISPs don't work through IPv6 yet — but if you do have one, it should match your active VPN's location, not your real one.
If your IPv4 address matches the VPN server but your IPv6 address does not, IPv6 is the likely cause of your leak.
Sam Chapman for Engadget
Should it turn out that you're leaking IPv6 requests, the easiest solution is to disable IPv6 on your computer. On Windows, you can do this through the network adapter options page of your control panel. Here's how to get there:
Windows 10: Start -> Settings -> Network & internet -> Status -> Change -> Advanced network settings -> Change adapter options.
Windows 11: Settings app -> Network & internet -> Advanced network settings -> Related settings -> More network adapter options.
On both OSes, finish the job by right-clicking the name of your internet connection, selecting Properties from the dropdown and unchecking the box next to Internet Protocol Version 6. Of course, you can always switch to another VPN that blocks IPv6 altogether, but you might find that to be a bigger hassle.
If you're on Mac, open System Settings, click the Network tab and then click the Details... button next to your network name. In the new window, click the TCP/IP tab on the left, find the entry labeled Configure IPv6 and set the dropdown to Link-Local Only.
5. Do streaming sites show different content?
A VPN can be working perfectly and still fail to unblock streaming sites. Netflix, HBO Max and the others block VPN traffic because VPNs can make them show material in regions where they don't hold the copyright. To avoid legal trouble, they set up their firewalls to block IP addresses known to belong to VPN servers.
If your VPN can't get into a streaming platform, it'll usually be obvious; the site will either display a proxy error message or simply refuse to load. However, in rare cases, the streaming site will load fine but show you the same shows you normally see. This indicates that you might be dealing with a VPN leak.
If that happens, follow the usual steps. Disconnect and reconnect to the same location to get a different server, then try different server locations. It's also possible that the streaming site is getting your real location from your browser cache, so if the problem persists, clear your cache and cookies and try again.
How to test a VPN kill switch
There's one more important step to make sure your VPN is working: test the kill switch. This common feature cuts off your internet connection if you lose touch with your VPN server. With your kill switch active, you shouldn't be at any risk of accidentally broadcasting your real IP address, location or online activity.
To test your kill switch, you'll need to simulate an abrupt loss of VPN connectivity. Open your VPN, make sure the kill switch is turned on, then connect to a server. Next, quit the VPN app without disconnecting. At this point, the kill switch should make it impossible for you to get online — if you can still browse the internet as normal, the switch might be faulty.
This article originally appeared on Engadget at https://www.engadget.com/cybersecurity/vpn/how-to-check-if-your-vpn-is-working-130000817.html?src=rss
The Federal Trade Commission lost its antitrust case against Meta last year, but the regulator hasn't given up on its attempts to punish the social media company for its acquisitions of WhatsApp and Instagram. The FTC is appealing a ruling last year in which a federal judge found that the government hadn't proven that Meta is currently operating as a monopoly.
"Meta has maintained its dominant position and record profits for well over a decade not through legitimate competition, but by buying its most significant competitive threats," the FTC's Bureau of Competition Director Daniel Guarnera said in a statement. "The Trump-Vance FTC will continue fighting its historic case against Meta to ensure that competition can thrive across the country to the benefit of all Americans and U.S. businesses.”
The FTC originally filed antitrust charges against Facebook in 2020 during President Donald Trump's first term in office. The government argued that by acquiring apps it once competed with, Instagram and WhatsApp, the company had depressed competition in the space and ultimately hurt consumers. A trial last year saw testimony from several current and former executives, including CEO Mark Zuckerberg and former COO Sheryl Sandberg, who spoke at length about the pressure to compete with TikTok.
US District Judge James Boasberg was ultimately persuaded by Meta’s arguments, writing that the success of YouTube and TikTok prevented Meta from currently "holding a monopoly" even if the company had acted monopolistically in the past. If the FTC had won, it could have tried to force Meta to undo its acquisitions of WhatsApp and Instagram. Should it be successful in its appeal, that remedy could once again be on the table.
News of the FTC's plan to appeal is also a blow to Zuckerberg, who has spent the last year courting Trump and hyping Meta's plans to spend hundreds of billions of dollars on AI infrastructure in the United States. In a statement, Meta spokesperson Andy Stone said that the original ruling was "correct," and that "Meta will remain focused on innovating and investing in America."
This article originally appeared on Engadget at https://www.engadget.com/big-tech/the-ftc-isnt-giving-up-on-its-antitrust-case-against-meta-225020769.html?src=rss
CyberGhost is the middle child of the Kape Technologies VPN portfolio, but in quality, it's much closer to ExpressVPN than Private Internet Access. I mainly put it on my best VPN list because it's so cheap, but I wouldn't have done that if it didn't earn its place in other ways — affordable crap is still crap, after all.
My universal impression of CyberGhost is a VPN that's not perfect but is always genuinely working to make itself better. It makes decisions based on what will help its users, not to set itself apart in a crowded market. This makes it similar to a lot of other VPNs, but that's not a bad thing — especially at such a low price.
Other than its price, the best things about CyberGhost are its intuitive app design, its frictionless user experience and the super-low latencies that make it an ideal pick for gamers. Download speeds are great up close but middling far away. While I love how many servers it's got in Africa and South America, a few too many of them are virtual locations. I'll get into all this and more in the review; feel free to read straight through or use the contents table to find the area that interests you most.
Editor's note (1/16/26): We've overhauled our VPN coverage to provide more detailed, actionable buying advice. Going forward, we'll continue to update both our best VPN list and individual reviews (like this one) as circumstances change. Most recently, we added official scores to all of our VPN reviews.Check out how we test VPNs to learn more about the new standards we're using.
Findings at a glance
Category
Notes
Installation and UI
Windows app has more options and the most sensible organization
macOS app is very easy to use, but a bit lacking compared to Windows
Android and iOS both have simple main pages and slightly confusing preferences
No browser extensions (free proxy doesn't count)
Speed
Excellent latency tests, with ping times short enough to lead the VPN field
Great download and upload speeds on close-in servers
Distant servers lag somewhat on both upload and download, bringing down the worldwide average
Security
Uses WireGuard, IKEv2 and OpenVPN protocols, but they aren't all supported on all platforms
Blocks IPv6 and prevents WebRTC and DNS leaks
Disconnects when switching servers
Pricing
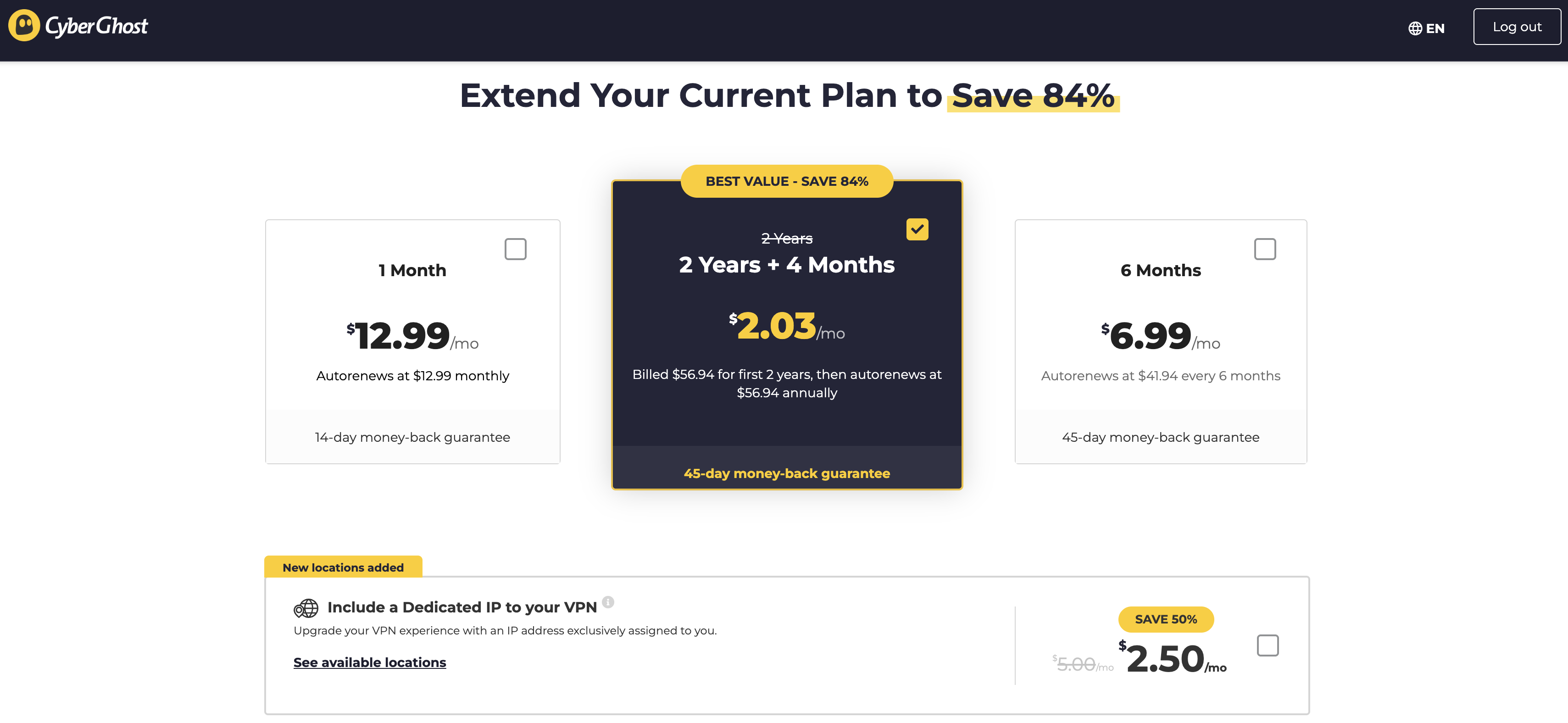
$12.99 per month
$41.94 for 6 months ($6.99 per month)
$56.94 for 28 months ($2.03 per month), renewing at the same price for 12 months ($4.79 per month)
Seven simultaneous connections
Bundles
Dedicated IP address for $2.50 per month
Privacy policy
Anonymizes all personal data
Can share data with other Kape subsidiaries, but only if they're based in areas with good privacy laws
RAM-only servers and full-disk encryption confirmed by audit
Has never given information to police
Virtual location change
Unblocked Netflix perfectly in five different regions using streaming-optimized servers and WireGuard
Server network
125 server locations in 100 countries
Good global distribution, with nine locations in South America and six in Africa
However, most servers in the southern hemisphere are virtual locations that may not give the best speeds
Features
Kill switch cannot be turned off except on Windows
Split tunneling by app on Android and by URL on Windows
Content blocker can only be turned on or off, no customization
Large network of torrent-optimized servers and streaming servers
Smart Rules automation is both user-friendly and deep
Customer support
Online help pages are well-written but poorly organized
Live chat responds quickly; there is a bot but it's easy to get past
Can also submit email tickets through an online portal
Background check
Founded in 2011 and based in Romania
Acquired by Kape Technologies in 2017
Installing, configuring and using CyberGhost
CyberGhost gets installation and UI largely right. There are no needless hurdles in the setup process. All its app designs put the important controls front and center and don't overload you with needless information. I've broken up my thoughts by platform, as CyberGhost is pretty different depending on where you use it.
Windows
CyberGhost downloads and installs amazingly fast on Windows 11. I didn't even have to grant any permissions. I just opened the .exe, clicked through a licensing agreement and logged into the desktop client. It took about two minutes end-to-end, including time I spent digging around in my password vault.
The CyberGhost VPN client for Windows 11.
Sam Chapman for Engadget
Once inside, you're greeted with a UI that looks an awful lot like Surfshark — and if it's not broken, don't fix it. Options for special servers are on the left, the server list is in the middle and the connection interface is on the right. The arrangement prioritizes the most important controls and keeps clutter to a minimum. The only thing I can find to complain about is that clicking on a country with multiple locations doesn't open the menu to choose between them; instead, you have to click on a hard-to-see arrow to the right of the name.
To access any of the special servers, click the appropriate tab in the left window, then choose from the list. Everything connects quickly. A gear icon at the bottom-left leads to all the special features and options, organized into three tabs: General (to do with the VPN app itself), CyberGhost VPN (to do with the VPN connection) and Account (to do with your subscription). The names could be better, but I can't argue with the clear and useful descriptions on each feature.
Mac
The download process on macOS Sequoia is as easy as it is on Windows 11. CyberGhost walks you through every step, installs its helper tools with minimal fuss and is ready to go out of the box. It's best to download directly from cyberghostvpn.com, since the App Store version is designed for iPads, not desktop computers.
Right after launching, the Mac app is pinned to the taskbar. To open it as a separate window, click the arrow button at the top-left. While it's in the taskbar, the only things you can do are connect, disconnect and switch to one of your favorite locations. You can do all that from the standalone window, too, so there's not much reason to ever leave it pinned.
CyberGhost's VPN client for macOS Sequoia.
Sam Chapman for Engadget
The interface on Mac differs from the Windows client in other noticeable ways. For one thing, it's permanently in dark mode, whereas Windows users get to choose between light and dark. There are fewer categories of servers in the left-hand column, with only torrenting (called For Downloading) and streaming options available — you can still connect to NoSpy, but only by going to the Romania location on the main list.
Also, the control panel gear is in the exact opposite location, sitting at the top-right of the connection window. The organization of options is also completely different and generally not as useful, with all the actual controls crammed into a single General tab.
This happened to me once or twice when my internet connection had no problems.
Sam Chapman for Engadget
Compounding the sense that CyberGhost didn't give its Mac app as much attention as its Windows app, I kept getting the odd error pictured in the screenshot above. The client would tell me I had no internet connection (my internet was fine) and direct me to run a connection test. This would always turn up all green lights and let me connect without any incident. It rarely tripped me up for more than a moment, but it was still bizarre.
Android
CyberGhost on Android is streamlined to the extreme, focusing on ease of use above all else. Connections happen quickly, and the server selection is narrowed down, with only the streaming locations getting their own tab. It's nice, but it does sometimes remind me of when I'd clean my room by shoving all the clutter under the bed.
CyberGhost connected on an Android phone.
Sam Chapman for Engadget
That's mainly because tapping the gear at the top-right opens up a preferences menu with a lot more going on than the main screen. Most of the options here aren't too complicated, but the shift is still jarring, especially since Android doesn't do as well as Windows at explaining what everything does. "Anonymous statistics" and "Share network data for troubleshooting" sound like the same thing to me, and we get nothing on the esoteric concept of Domain Fronting.
Still, I'm nitpicking a bit. CyberGhost's Android client does 95 percent of its job very well. Most of the settings aren't necessary anyway, so you can pick your favorite server and be on your way.
iOS
Much like its Android app, CyberGhost's iOS offering is sleek on the front end, a little cluttered in the back, but overall quite easy to use. Connections happen within seconds. The main page includes a useful option to tap on your current Wi-Fi network and immediately set Smart Rules for it. As with Android, only streaming-optimized servers and favorites are separated from the rest.
The main page of CyberGhost's iPhone app.
Sam Chapman for Engadget
The control panel also looks very similar to what you get on mobile. The apparent clutter comes from simple on-off toggles and more complex submenus being all jumbled up together, but you can use the VPN just fine without engaging with any of it. For the most part, CyberGhost on iOS does a lot to help you and nothing to get in your way.
Browser extensions
CyberGhost doesn't have a full-service browser extension. If you look for an extension link on the download hub, you won't find anything. What it does have is free proxy add-ons for Chrome and Firefox, which can be used to change your IP address to a new location.
However, proxies do not encrypt your traffic, leaving out one of the critical aspects of how a VPN works. The extension library pages for the CyberGhost proxies are vague about this, but they're no substitute for a full VPN. They're free and may be convenient for occasional streaming if they don't get caught, but they aren't secure.
CyberGhost speed test
I conducted all these tests on a wireless connection using the WireGuard protocol. For each, I selected either a physical server or a virtual location close to its physical source. Here's what each metric means in the table below:
Ping, measured in milliseconds (ms), is a measure of latency — how long it takes to send a signal from your device to its destination via the VPN server. Lower pings are better. Since signals can only move so quickly, latency tends to increase with distance.
Download speed, measured in megabits per second (Mbps), is what you probably think of as "internet speed" — how fast websites load and how much video you can stream without any pause to load.
Upload speed, also measured in Mbps, determines the rate at which data travels from your device to its destination. It's useful for posting content, saving files to the cloud, torrenting and two-way video calls.
Server location
Ping (ms)
Increase factor
Download speed (Mbps)
Percentage drop
Upload speed (Mbps)
Percentage drop
Portland, USA (unprotected)
16
—
58.70
—
5.80
—
Seattle, USA (fastest location)
22
1.4x
55.88
4.8
5.60
3.4
New York, USA
155
9.7x
45.43
22.6
5.43
6.4
Montevideo, Uruguay
111
6.9x
46.25
21.2
5.55
4.3
Lisbon, Portugal
328
20.5x
45.60
22.3
4.36
24.8
Johannesburg, South Africa
632
39.5x
34.12
41.9
3.68
36.6
Vientiane, Laos
350
21.9x
38.04
35.2
4.78
17.6
Average
266
16.6x
44.22
24.7
4.90
15.5
CyberGhost's speed test gave me mixed results — mostly good, but with some reasons for caution. To start on the positive side, latency results were excellent. No matter where I went in the world, the numbers only jumped above 400 milliseconds in one place, and that was the Johannesburg server that had problems across the board. CyberGhost's 266 average is significantly better than I got when testing Surfshark, currently the fastest VPN overall.
A speed test using the fastest location chosen by the CyberGhost app.
Sam Chapman for Engadget
Download and upload speeds looked good in my fastest location, Seattle. Using CyberGhost only slowed my browsing by 4.8 percent and dropped my upload rates by 3.4 percent, comparable to most of its leading competitors. At a distance, though, speeds started to falter. Things in New York remained reasonably fast, but with a lot of fluctuation between tests; unlike Seattle, numbers swung between the 30s and 50s.
As I virtually traveled the world, I saw more and more swings, plus sharp declines in South Africa (which is always the problem child of VPN servers, for some reason). To put this in perspective, CyberGhost never dragged that much on my browsing speed, and the internet remained usable no matter where I went. It's just slightly more sluggish than my favorite VPNs in every area — except latency, where it soars ahead.
CyberGhost security test
VPNs need to secure your internet activity against two things: intentional attacks and leaks due to negligence. A VPN should be watertight enough that it never lets your information slip by accident, while also defending your data against outside interference.
It's not hard to test whether a provider is meeting these two criteria. First, make sure it's using safe VPN protocols with modern encryption. Second, use an IP address checker to test for DNS, WebRTC and IPv6 leaks. Third, test encryption itself to ensure it's being applied equally to all data packets. Let's get started.
VPN protocols
CyberGhost supports three different VPN protocols, all of them up-to-date and secure. OpenVPN, available on Windows, Android, Linux and Fire TV, is my typical recommendation, balanced and secured through a multi-decade history of refinement. WireGuard, supported on every platform, is the new hotshot on the block, fast and stable but not quite as rigorously tested as OpenVPN. IKEv2, which works on macOS, iOS and Windows, connects more quickly than the others but isn't open-source.
I have some quibbles about how available these protocols are. OpenVPN should always be an option for everybody; leaving it off Apple devices doesn't make sense. I’ve asked CyberGhost about this and will update here when I get a reply. In the meantime, I can't complain about the protocols themselves, which use uncracked encryption ciphers and present no obvious weak points.
Leak test
I used ipleak.net to check CyberGhost for leaks. There are three likely causes for a VPN to accidentally reveal your real IP address: it failed to account for different IP types (IPv6 leak), a real-time connection went outside the encrypted tunnel (WebRTC leak) or it used a domain name server that an ISP could read (DNS leak).
CyberGhost never leaked my real IP address.
Sam Chapman for Engadget
CyberGhost blocks all IPv6 traffic, so there's no chance of an IPv6 leak. I checked for WebRTC leaks and didn't find any. Likewise, every time I connected to a VPN server and refreshed the page, I saw that server's IP address, proving that CyberGhost isn't leaking.
There is one important exception here: whenever you select a different server on your CyberGhost client, it disconnects from that server before connecting to the next one. This means that your data is exposed during the transition. It's annoying, but as long as you remember not to do anything risky while changing locations, you'll be fine.
Encryption test
For my final test, I used WireShark to capture images of the data packets CyberGhost was routing from my device to its servers. Sure enough, the outer layer of each data stream was encrypted no matter which VPN protocol I used. Ultimately, all my probing showed that CyberGhost is secure against both negligence and interference.
How much does CyberGhost cost?
CyberGhost sells three different subscriptions, all of them with the same features. The only difference is how long the plan lasts. You can save money overall by signing up for six months or two years at a time, but it costs more upfront. Each plan can be used on seven devices simultaneously.
These prices are subject to change.
Sam Chapman for Engadget
One month of CyberGhost costs $12.99, and it renews automatically at the same price at the end of each billing month. Each monthly renewal comes with a 14-day, money-back guarantee. You can get six months for $41.94 total, which works out to $6.99 per month. At the end of six months, it auto-renews at the same price. The six-month plan comes with a 45-day refund guarantee.
Finally, there's the two-year plan, which comes with a lot of fine print. The first time you sign up, it costs $56.94, which gets you a total of 28 months (working out to $2.03 per month). However, after your 28 months are up, all subsequent renewals instead get you a 12-month plan — still for $56.94, but now working out to $4.79 per month. That's still relatively cheap, but not nearly as affordable as some VPNs with perpetual two-year plans.
CyberGhost side apps and bundles
CyberGhost doesn't have much in the way of additional subscription offers, but that's honestly refreshing. In an age when even the best providers also need to be antiviruses, insurance agents and probably vacuum cleaners, it's nice to see a VPN that's content with just being a VPN.
CyberGhost does have a broader "security suite," but it comes at no extra cost and is currently available on Windows only. More info on that in the "Extra features" section below.
Dedicated IP
You can pay an extra $2.50 per month to add a dedicated IP address to your CyberGhost plan. With a dedicated IP, you'll have a stable address whenever you get online through the VPN, which makes it a lot easier to connect to firewall-protected web services. It's also exclusive, so nobody else can get you in trouble by misusing the IP address.
Close-reading CyberGhost's privacy policy
CyberGhost is located in Romania, which makes it subject to the strict privacy laws of the European Union. It's not legally required to keep tabs on its users or install government backdoors. That's a great start, but to be certain about a company's approach to privacy, it's best to look at its own words.
A VPN makes your online activity anonymous to anyone else who tries to look at it, but the VPN itself still has the power to violate your privacy if it chooses. This leads some people to advise against using commercial VPN services at all, though I don't go that far. The best VPNs build in features that make it impossible for them to abuse their access to your web traffic, such as RAM-only servers and full-disk encryption.
When trying to determine if you can trust a VPN with your privacy, the first place to look is its official privacy policy. This document lays out everything the VPN does to handle your personally identifiable information (PII). If the provider violates its policy, they can be sued, so it's not in their interest to lie outright in the document.
I went over CyberGhost's privacy policy with a fine-toothed comb — it can be found here if you'd like to follow along. It starts with the usual promise of "uncompromising protection": CyberGhost swears that "we are NOT storing connection logs, meaning that we DON'T have any logs tied to your IP address, connection timestamp or session duration" (all emphasis theirs).
That's the standard I'll be checking against: a total lack of any way for CyberGhost to read or share information on its own users. Let's see how it holds up.
These may just be words, but they have legal force, at least in civil court.
Sam Chapman for Engadget
The privacy policy wins early points by clarifying all the data it collects. You can see the whole quote in the screenshot above, but to summarize, any PII (like your email or IP address) will never be connected with anything you do online. Since absolute anonymity is impossible, this is the best we can hope for from a VPN.
Later on, the policy clarifies everything CyberGhost might do with personal data, none of which involves turning it over to authorities or selling it to advertisers. The most suspicious reasons given are "fraud detection/prevention" and "To enforce the terms of service," but these both relate to kicking users off CyberGhost itself, not tattling on them to the government.
The only potential problem comes in the section titled "Sharing Your Personal Data." Here, CyberGhost states that "we may communicate your personal data to a member of our group of companies," meaning all subsidiaries of Kape Technologies. I won't rehash the case against Kape in full — my ExpressVPN review covers it in detail.
Suffice to say the only real risk here is that CyberGhost might share PII with another Kape company located in a region with worse privacy laws than Romania or the EU. To me, this isn't a serious concern. First of all, Kape doesn't own any companies based in truly anti-privacy nations like China, India or Russia.
Moreover, the privacy policy states that CyberGhost won't share information with any entity not "located in the EU or another jurisdiction offering equivalent data protection standards." Every bit of data gets the same protections. This may mean PII enters a country in the Five/Nine/14 Eyes alliance, but the Eyes only matter if a VPN is already logging data it shouldn't have. It's not that abuse of intelligence-sharing agreements isn't a problem; it's just that the risk it poses starts with the VPN itself, not where it's located.
To sum up, I didn't see any red flags or loopholes in the CyberGhost privacy policy. Some clauses could be tightened up, and it always pays to be suspicious, but I'm confident that using this VPN doesn't risk your personal privacy.
Independent corroboration
CyberGhost has been audited twice by Deloitte Romania, once in 2022 and again in 2024. Following that pattern, I'll be looking out for another one this year. You need an account to read the full audit report, but it's only 10 pages and easy to summarize: the auditors found nothing in CyberGhost's systems that conflicted with its privacy policy.
The audit notes CyberGhost's server infrastructure as evidence. All servers are run on RAM with full-disk encryption, making any information they store completely ephemeral. Even if CyberGhost staff wanted to spy on you, they wouldn't see anything. The same goes for third-party hackers.
CyberGhost also posts a regular transparency report that lists how often law enforcement has asked it for information. As far as I could find, after hundreds of requests, there's never been a case where CyberGhost provided any information to cops.
Can CyberGhost change your virtual location?
For this section, I used Netflix to test whether CyberGhost's virtual location changes are detectable by other websites. Ideally, every time I change location with CyberGhost, Netflix would accept it as real and show me the content library from that country. If either of those things doesn't happen within three tests, the VPN has a problem.
Since CyberGhost has servers built for streaming, I used those for each of the five locations. You can see my results below.
Server location
Unblocked Netflix?
Changed content?
United Kingdom
3/3
3/3
Japan
3/3
3/3
Germany
3/3
3/3
Australia
3/3
3/3
Brazil
3/3
3/3
This test was a smashing success for CyberGhost. Every time, it showed me the proper video library for the location I chose and never once got caught by Netflix's firewalls. It's the best result I've seen in this section since I tested Proton VPN, and that's high praise if you know me.
CyberGhost has 125 server locations in 100 countries. Of those locations, 75 are real and 50 are virtual, which makes the math easy: CyberGhost's VPN server network is 60 percent bare-metal and 40 percent virtual. That's good, since physical servers let you calculate how much performance will deteriorate over distance — virtual servers are just as safe, but speeds might fluctuate depending on where they really are.
Region
Countries with servers
Total server locations
Virtual server locations
North America
9
21
5
South America
9
9
9
Europe
45
56
13
Africa
6
6
3
Middle East
6
6
4
Asia
23
23
16
Oceania
2
4
0
Total
100
125
50
Looking at the distribution of servers, we get good news and bad news. The good news is that there really are 100 different countries and territories to choose from, encompassing nearly all the virtual globetrotting you're likely to need. There are also lots of servers in the southern hemisphere, which is often the last place VPNs grow into. There's a wealth of choices in South America, plus several options in Africa and Central Asia.
CyberGhost's selection of VPN servers.
Sam Chapman for Engadget
The bad news is that the distribution of real servers is skewed toward Europe and the United States. None of the nine South American servers are actually located in South America; worse, a large number of them are physically located in Miami. If you're using CyberGhost in Argentina, don't expect top speeds from the Buenos Aires server, since it's actually over 4,000 miles away. CyberGhost's support center does include a list of where the virtual servers are relayed through, but it's not up to date.
Extra features of CyberGhost
CyberGhost has a few features beyond the VPN itself, though not as many as you might think. Compared to a provider like NordVPN, which goes all in on extra features, CyberGhost's offerings look pretty lean. But that doesn't matter as much if the features work well. Let's see how they do.
Kill switch
CyberGhost takes an unusual approach to its kill switch. In case you aren't familiar with the term, a kill switch cuts off your internet connection if your link to the VPN ever drops, protecting your anonymity in case of unexpected incidents. Most VPNs let you toggle the kill switch on and off, but on CyberGhost, it's fully engaged 100 percent of the time — except on Windows, where you can turn it on and off as desired.
Turning on the kill switch is almost always a good idea, but it's still annoying that Cyberghost gives many of its users no way to turn it off. In rare cases, kill switches can get overzealous, preventing you from getting online even when conditions are safe. It's an odd choice to remove a potential troubleshooting step from the user's control.
Split tunneling
Split tunneling lets you name some apps or websites that will run unprotected even while the VPN is active. This can help with certain services that refuse to work if they detect a VPN, or alternatively, can protect only one sensitive app or site while the others enjoy faster unprotected speeds.
CyberGhost only has full split tunneling on Android. It also offers a slightly different feature called Exceptions on Windows. Android split tunneling works by app, while Exceptions works by URL. In both cases, you choose individual apps or websites to leave out of the VPN. It's limited, but works as advertised.
Optimized servers
As I mentioned in the Netflix testing section, CyberGhost includes specialized servers designed for specific tasks. Other than the add-on dedicated IP servers, these come in four forms: "For gaming," "For torrenting," "For streaming" and "NoSpy." Gaming servers are apparently built to keep latency low, but I couldn't see much difference between them and the normal servers.
"For torrenting" is called "For downloading" on Mac, but it's all the same torrent-optimized servers. These are built to meet the download and upload speed requirements for effectively using P2P filesharing clients. CyberGhost has P2P servers in 86 countries, which makes it a good VPN for torrenting; only the lack of port forwarding keeps it from being truly great.
A few of CyberGhost's specialty servers on a MacBook.
Sam Chapman for Engadget
Each streaming server is built to unblock a specific streaming site in a particular country, occasionally for a single type of device. For example, United States streaming servers are aimed at Netflix, Hulu, Peacock, Disney Plus, Amazon Prime Video and more, many in their Android or Smart TV forms. UK servers work for Netflix UK, BBC iPlayer, ITV and more. In total, there are 106 streaming servers in 22 countries — not quite as extensive as the overall list, but it's important to remember that non-optimized servers still work fine for streaming.
Finally, the NoSpy options connect to a set of servers in Romania that CyberGhost claims to manage entirely in-house, with nobody able to access them except CyberGhost's own team. This is good, but it leaves me suspicious about who's running the rest of the servers. Are they all run by third parties except the NoSpy locations? That's relatively common, but it creates vulnerabilities if the VPN provider doesn't insist on high standards from collaborators.
Content blocker
CyberGhost's content blocker is underwhelming. All you can do is turn it on and off. There's no customization like you get with Windscribe's R.O.B.E.R.T. and no clear statement of where it's getting its list of domains to block. In practice, it does block in-page ads, but without specifics I couldn't test it in more detail.
There's no customization on CyberGhost's blocker -- just turn it on or off.
Sam Chapman for Engadget
Smart Rules
The Smart Rules automation suite is the crown jewel of CyberGhost's features and the most common reason I recommend it. Using Smart Rules, you can automate CyberGhost's behavior to a degree inconceivable on most other VPNs.
You can program CyberGhost to take different actions on each of your usual networks.
Sam Chapman for Engadget
Smart Rules come in two forms: actions performed automatically when CyberGhost launches or connects and actions that respond to new Wi-Fi networks. In the former category, you can set CyberGhost to connect when you open the app, determine which location it connects to and even set an app to automatically open after it connects.
Wi-Fi rules depend on whether the network CyberGhost detects is secured or not. For each type of network, you can set the VPN to connect, disconnect, ask you what to do or ignore it entirely. Once it recognizes a Wi-Fi network, you can set specific rules for that network. It's at once very easy to use and capable of surprising depth.
CyberGhost customer support options
CyberGhost primarily offers customer assistance through its online portal, which can be reached at support.cyberghostvpn.com or by going through the app. If you choose the options "CyberGhost VPN help" or "FAQ" in the app settings, you'll be taken to the support pages in a browser. I recommend going through the URL, since that takes you to the highest-level page.
The support center feels distressingly like an afterthought. Written guides are divided into four sections: Guides, Troubleshooting, FAQs and Announcements. The latter has only one article and the former three are roughly interchangeable — if I'm having trouble connecting to a server, is that an FAQ, a Guide or Troubleshooting? Looking for any particular subject here is a needle-in-a-haystack search.
Fortunately, there is a search bar, but this presents its own problems. A simple search for "connection issues macos" turned up 72 results, including one called "Troubleshooting connectivity on macOS" and another titled "Troubleshooting VPN connection on mac." These two articles are in different sections, but mostly contain the same information, except that the former has an extra walkthrough on renewing your DHCP lease.
It's a shame, because the articles themselves are mostly clear and helpful, with lots of well-chosen screenshots. Someone clearly worked hard on the content, but the overall organization left me thinking the knowledgebase was thrown together years ago and hasn't been checked since.
Live support experience
If you have trouble finding what you need in the written guides, you can get personal support in two ways. One option is to submit an email request through a Zendesk portal. This gives you all the time you need to frame your question and add supporting materials, at the cost of waiting longer for a reply.
Your other option is to access live chat, which you can do from anywhere on cyberghost.com by clicking the chat button in the bottom-left corner of the screen. Live chat starts with a "CyberGhost AI Assistant" (what we used to call a chatbot in the good old days) which runs you through several diagnostic questions. To its great credit, the bot does not try to link you to articles in the knowledgebase, understanding — as too many providers don't — that nobody tries live chat unless the FAQ isn't working for them.
It didn't take me too long to get in touch with what was apparently a live expert.
Sam Chapman for Engadget
I decided to bother CyberGhost about the connection issue I wrote about in the Mac UI section. Within seconds, the chatbot offered me a button that would transfer me directly to a live agent. I only had to wait about 4 minutes before the agent got in touch. After that, each response took about a minute and explained everything carefully and efficiently. It was as helpful as the written knowledgebase wasn't.
CyberGhost background check
CyberGhost was founded in 2011 in Bucharest, Romania, where it's still headquartered today. It claims to have around 38 million subscribers and a staff of 70. It appears to be most popular in France and Germany.
The only thing that makes me at all uncertain about CyberGhost is that I can't find much information about its history — it doesn't even have a Wikipedia page in English. By far the most likely explanation is that CyberGhost is exactly what it seems to be: a reliable, drama-free VPN provider that doesn't court controversy. Still, I'm naturally paranoid, so I'd understand if this lacuna sends you running back to a better-documented VPN.
There is precisely one date in CyberGhost's history that everyone lists: 2017, when it was purchased by Kape Technologies. As a VPN reviewer, I have to think about Kape a lot. My opinion is that the fear around it doesn't measure up to reality. For example, back when it was known as Crossrider, Kape was not a "malware distributor"; it sold an ad-injection plugin that turned out to be a useful malware vector.
Perhaps Crossrider could have worked harder to stop its platform from being misused, but that doesn't make it a security threat today. Similarly, being owned by a businessman from Israel does not mean that Kape or CyberGhost are secretly controlled by Mossad.
I'm not here to defend Kape — I'm just pointing out that a lot of the fear isn't backed up by evidence. To my mind, Kape's consolidation of the VPN industry (it also owns ExpressVPN and Private Internet Access, plus two websites that review VPNs) is bad enough without having to look for additional conspiracies. It's up to you to decide whether or not CyberGhost's parent company presents a hard line you won't cross.
Final verdict
At the end of my journey with CyberGhost, I may not be blown away, but I'm definitely pleased. After my poor experience with PIA, I was afraid the only budget VPN I could wholeheartedly recommend was a two-year subscription to Surfshark. CyberGhost is a meat-and-potatoes VPN — it's not pushing any envelopes, but it's cheap and it does the job.
All that said, I recommend it more to casual users than to people who really need secrecy. There are just enough reddish flags that I wouldn't necessarily trust it with life-and-death information: the (possible) use of third-party managers for all servers outside Romania, the freedom to share information with any Kape subsidiary, the loss of encryption when switching servers. It'll keep you anonymous and let you stream foreign TV for cheap, but you should still choose Proton VPN if you need serious privacy.
This article originally appeared on Engadget at https://www.engadget.com/cybersecurity/vpn/cyberghost-vpn-review-despite-its-flaws-the-value-is-hard-to-beat-200000250.html?src=rss