AI assistants have mostly lived inside screens, and that’s been fine, until you’re deep in a coding session and Claude is quietly running shell commands, editing files, and hitting tool after tool in the background. Knowing what’s happening without constantly alt-tabbing is harder than it should be, and approving or denying an action while keeping your hands on the keyboard is even harder.
That’s the gap Claude Desktop Buddy was built to fill. Released as an open-source project by Anthropic in April 2026 and built as a prototype by OpenELAB, it turns a small ESP32-based device into a physical companion that sits on your desk and mirrors the activity of the Claude desktop app over Bluetooth Low Energy. It wakes when a Claude Code session starts, idles quietly while Claude works, and gets visibly impatient when a permission prompt is waiting for your attention.
Designer: Anthropic, OpenELAB


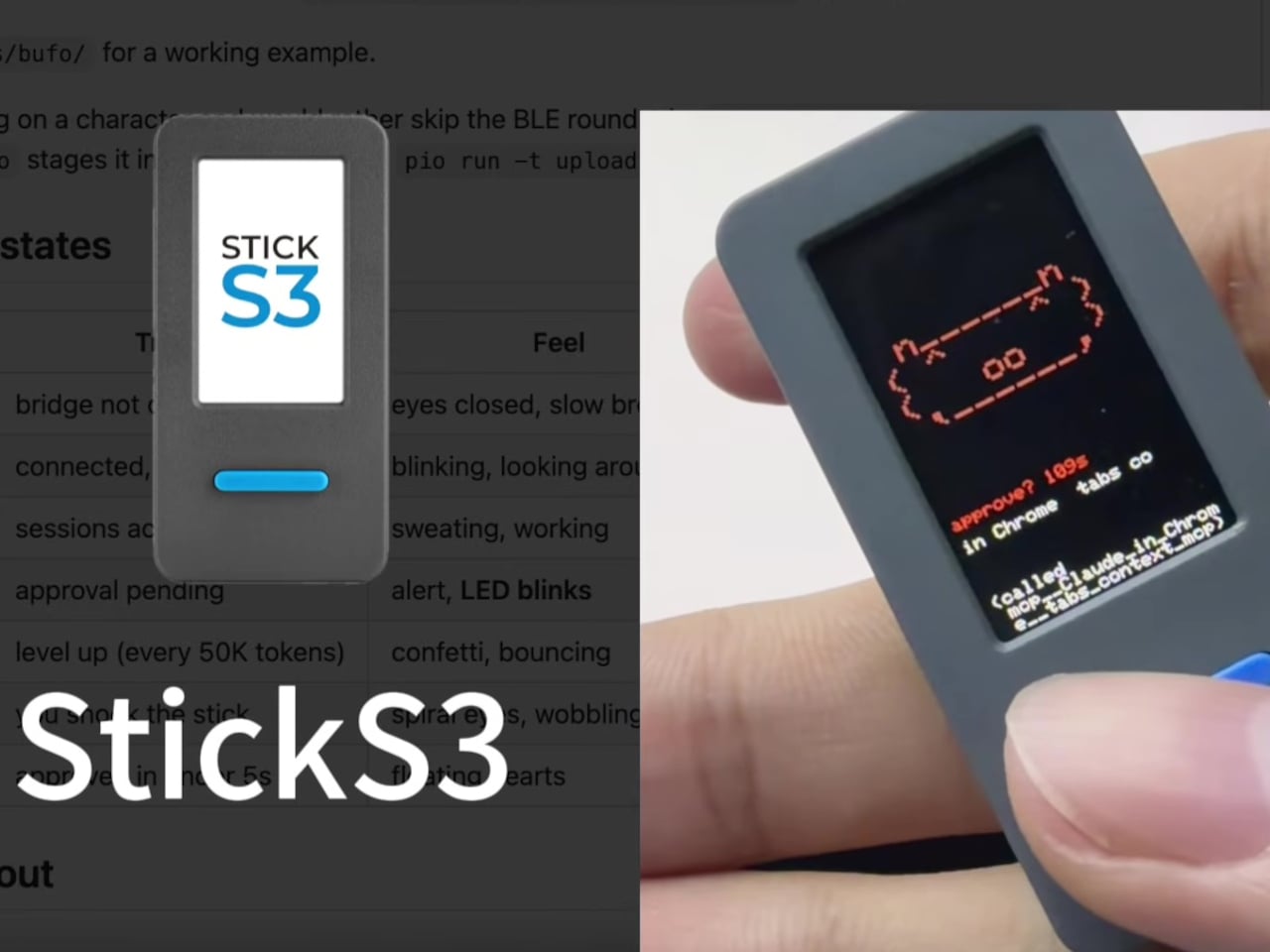
The reference hardware is the M5StickC Plus, a pocket-sized board with a 135×240 color display, buttons, a built-in IMU, and a LiPo battery. It costs around $30 and comes pre-supported by the firmware. When Claude Code asks to run a shell command or access a sensitive file, the device lights its screen, buzzes, and shows the prompt. Button A approves. Button B denies. No switching windows, no hunting for the right modal.
Beyond the permission workflow, the device also doubles as a passive status indicator. A full vocabulary of animated states, including idle, busy, attention, celebrate, dizzy, and heart, plays out on the small screen depending on what Claude is doing. Shake the device to make it dizzy, flip it face-down to put it in nap mode, and it’ll power off the screen after 30 seconds to preserve battery. The built-in IMU handles all of this through physical gestures.
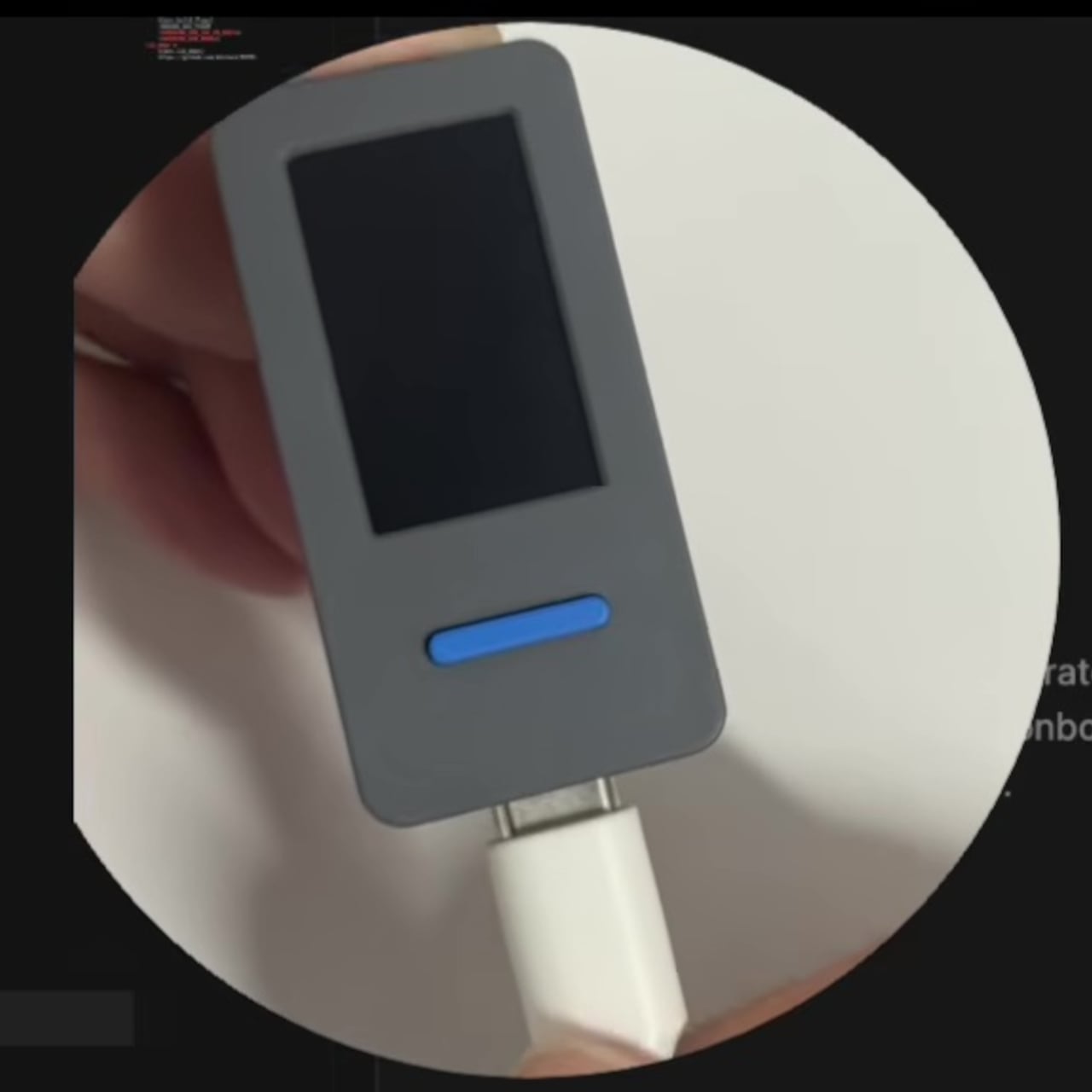

Transcript scrollback is another feature that makes more sense once you’ve used it. Rather than breaking focus to check what Claude just said, you can scroll recent messages directly on the device’s display. It keeps the primary workflow uninterrupted in a way that alt-tabbing simply doesn’t. The device pairs once and reconnects automatically whenever both sides are awake, so there’s no daily setup ritual.
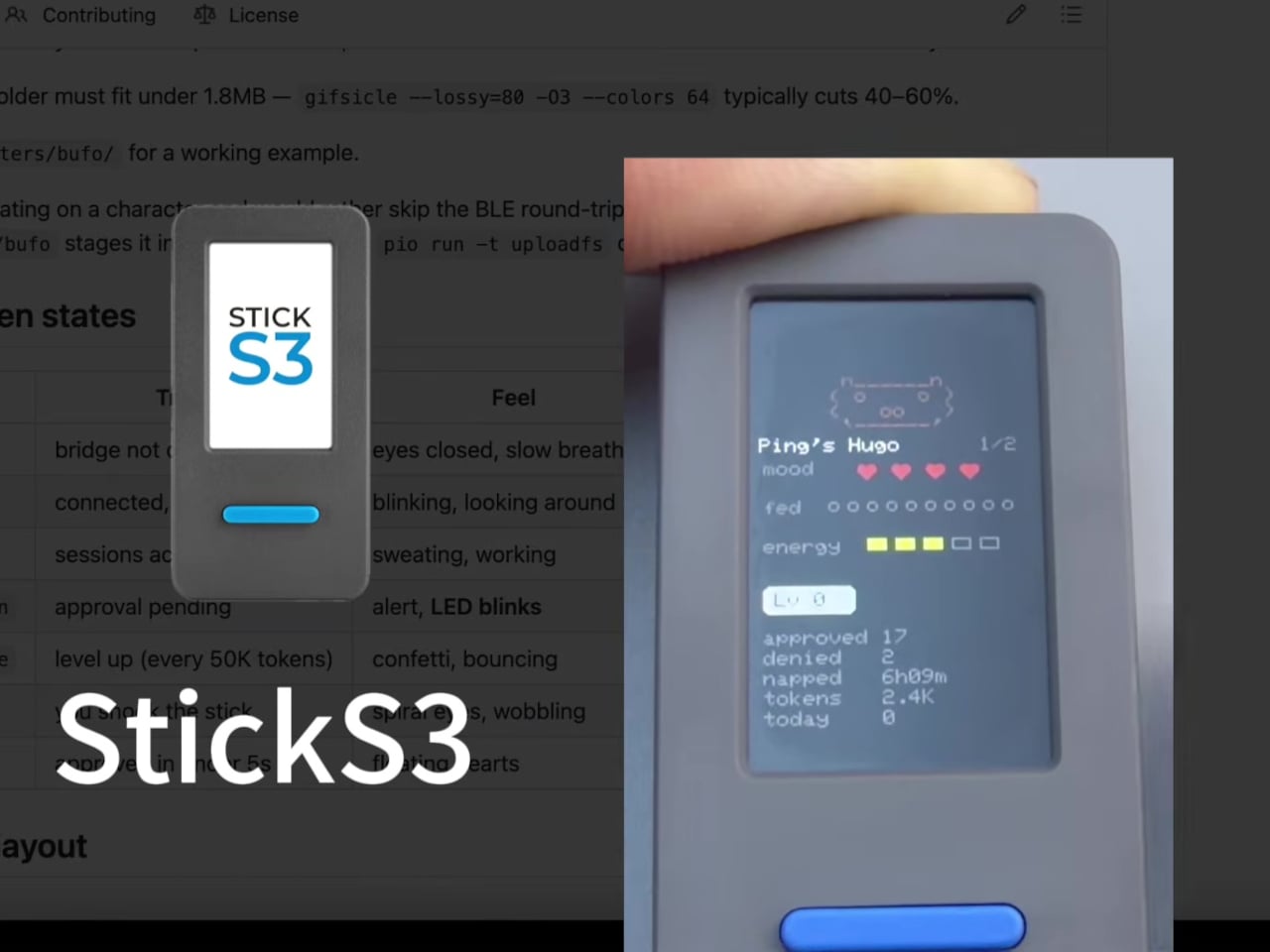
Character customization adds a layer of personality that feels unexpectedly considered for what is, technically, a developer tool. You can drag a custom GIF character pack directly onto the Hardware Buddy window, and the device switches to the new character live. The default character, a small frog called Bufo, ships with the firmware.
There’s something genuinely different about having a physical object on your desk that reacts to an AI working in the background. It turns an invisible process into something with a face, a mood, and a pair of buttons that put control back in your hands without disrupting what you were doing.
The post This $30 Gadget Gives Claude a Face That Reacts to What It’s Doing first appeared on Yanko Design.